Инженеры Google описали ключевой изъян машинного обучения, приводящий к ошибкам ИИ
Тема искусственного интеллекта в последние годы стала невероятно популярной. Однако, несмотря на все достижения в этой области, ИИ по-прежнему чаще человека ошибается практически в любом классе задач. Специалисты Google сформулировали один из ключевых недостатков важнейшего компонента создания искусственного интеллекта — машинного обучения — и предложили способ его компенсации.
Научная работа опубликована на портале arXiv. В ней описано понятие недостаточной детализации (underspecification) в машинном обучении (machine learning). Авторы указывают на то, как в привычном процессе обучения нейросетевых алгоритмов слишком часто возникают неочевидные поначалу аномалии. В результате обученный таким образом алгоритм будет выдавать непредсказуемые или ошибочные выводы.
По мнению команды специалистов из Google, проблема в следующем. Во время обучения алгоритма на некоем наборе данных искусственный интеллект может сделать не совсем то обобщение, которое считают необходимым или эффективным его создатели. И сам по себе этот факт не является чем-то негативным, наоборот — в этом и есть «сила» нейросетей. Но, тренируя алгоритм, программисты не учитывают и далеко не всегда могут знать, что именно он выбрал в качестве дополнительных критериев. В итоге, классифицируя результаты как точные и неточные, человек обучает ИИ не совсем тому, чему хотел.
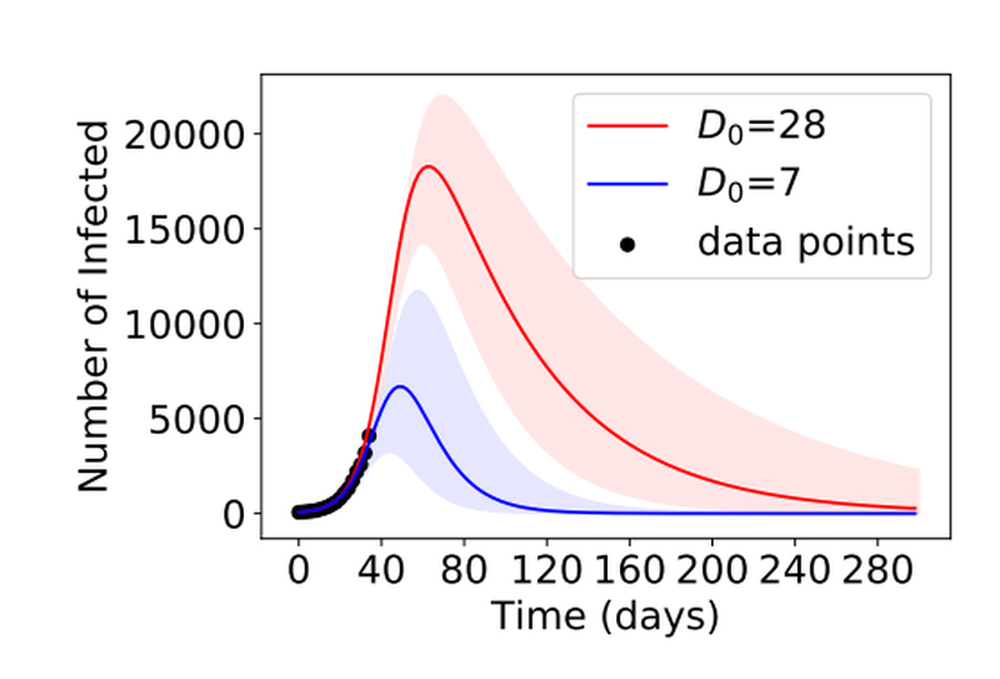
Результатом подобного обучения могут стать непредсказуемые ошибки. Например, в эпидемиологии есть математическая модель, описывающая течение эпидемии. Она строится на ключевых параметрах: коэффициенте распространения инфекции (R0) и продолжительности времени, пока заболевший заразен (D). Теоретически даже на ранних стадиях пандемии можно проанализировать эти данные по нескольким случаям и предсказать ее ход. Это крайне важно для властей и медиков, которые будут иметь понимание, когда переполнятся больницы и в какой момент и как нужно реагировать на статистику.
Однако на практике обученный по массивам медицинских данных искусственный интеллект может выдавать разные предсказания. И выбор из них реалистичного — нетривиальная задача. Дело в том, что во время обучения алгоритм будет учитывать множество побочных параметров. Так же делают и люди, но они могут объяснить свои решения, а ИИ — нет. Таким образом, необходимо еще на стадии создания алгоритма и его обучения учитывать все больше параметров. В этот момент появляется второе ключевое ограничение.
Подобных второстепенных параметров может быть огромное количество, и далеко не все из них будут так же важны для человека, как для нейросети. Фактически предсказать только по результату (прогнозу) модели, на основании каких второстепенных факторов была достигнута нужная точность, невозможно. И тем более нельзя сходу оценить, как именно изменится работа алгоритма при других масштабах поступающих данных. Свои соображения авторы описываемой работы наглядно и подробно иллюстрируют четырьмя примерами, в которых ИИ либо традиционно считается более точным, чем человек, либо его использование предполагается наиболее перспективным. Речь о компьютерном зрении, распознавании медицинских изображений и речи , а также медицинских предсказаниях на основе статистики.
Однако не все так ужасно. Авторы работы предлагают методику стрессового тестирования искусственного интеллекта. По их мнению, можно ввести в процесс машинного обучения обязательные стресс-тесты на специально подготовленных данных. Они могут быть нарочно выходящими за рамки моделей или хорошо изученными экстремальными примерами из реальной жизни. В любом случае с их помощью будут сразу обнаружены основные аномалии алгоритма.
Несомненно, озвученные сотрудниками Google идеи не являются революционными и зачастую используются на практике. Но они еще не стали стандартом даже в самых критичных для нас областях применения ИИ. И, конечно, для многих профессионалов вышеописанная работа может выглядеть простой и очевидной. Тем не менее в ней от элементарных моделей до сложнейших симуляций показано влияние недостаточной детализации на результат. Кроме того, авторы работы собрали воедино идеи и выводы из колоссального количества публикаций на смежные темы. Это позволяет назвать ее отличным промежуточным итогом в развитии современных наработок в области ИИ.
 Telegram
Telegram  Дзен
Дзен Инфекции, такие как коронавирус, наносят серьезный удар организму, из-за чего даже после выздоровления он продолжительное время остается уязвимым. Сегодня для оценки иммунитета врачи смотрят в первую очередь на уровень антител в крови, однако такой подход не отражает реального состояния здоровья человека. Это не позволяет врачам точно прогнозировать, как будет протекать болезнь и насколько быстро пациент выздоровеет. Ученые Пермского Политеха и ПГАТУ впервые выяснили, как именно восстановление иммунитета зависит от пола человека и кто наиболее подвержен осложнениям после коронавирусной инфекции. Результаты исследования помогут правильно учитывать гендерные особенности пациента при лечении и реабилитации, что повысит точность прогнозов и эффективность терапии.
Плавящийся асфальт в США, многие тысячи погибших в Западной Европе, своеобразное лето в России — все это списывают на вредоносный феномен рекордного Эль-Ниньо. И конечно же, на него спихивают и ожидаемый рост цен на кофе и основные сельхозтовары. Правда, есть в этой картине и белые пятна: в прошлые Эль-Ниньо мировые урожаи росли. Что скорее всего случится в 2026 году и отчего роль этого события может быть куда больше, чем мы думаем?
Ученые МИЭМ ВШЭ предложили математическую модель, которая позволяет понять, как взаимодействие между сообществами влияет на их устойчивость. Работа основана на классической теории эволюционных игр и демонстрирует неожиданный эффект: даже небольшое информационное воздействие одного сообщества на другое может привести к тому, что одно из них сохранит внешнюю стабильность, а в другом начнутся хаотические изменения на уровне отдельных участников.
Анализ более 150 тысяч древних звезд Млечного Пути показал, что возраст космоса, судя по всему, близок к 13,8 миллиарда лет. Авторы нового исследования заключили, что сценарии, в которых Вселенную приходится делать заметно «моложе» ради решения хаббловского кризиса, плохо согласуются с наблюдениями. Это важно, поскольку возраст старейших светил — один из немногих независимых способов проверить космологические модели не по данным ранней Вселенной, а по объектам нашей собственной Галактики.
Сканирующая туннельная микроскопия достигла квантово-механического предела пространства-времени. Физики провели эксперимент и смоделировали перемещение одиночного электрона с атомарной точностью и скоростью в доли фемтосекунды. Результат показал границы применимости квантовых законов и объяснил механику сверхбыстрых процессов.
Инфекции, такие как коронавирус, наносят серьезный удар организму, из-за чего даже после выздоровления он продолжительное время остается уязвимым. Сегодня для оценки иммунитета врачи смотрят в первую очередь на уровень антител в крови, однако такой подход не отражает реального состояния здоровья человека. Это не позволяет врачам точно прогнозировать, как будет протекать болезнь и насколько быстро пациент выздоровеет. Ученые Пермского Политеха и ПГАТУ впервые выяснили, как именно восстановление иммунитета зависит от пола человека и кто наиболее подвержен осложнениям после коронавирусной инфекции. Результаты исследования помогут правильно учитывать гендерные особенности пациента при лечении и реабилитации, что повысит точность прогнозов и эффективность терапии.
Хотя длительность помех не превышала десяти секунд, это первый известный случай такого рода. Обычно спутникам не хватает мощности для создания радиосигналов той силы, что нужна для подобных помех.
Вселенная может оказаться «замкнутой» глобальной структурой, где свет от далеких галактик способен возвращаться к наблюдателю с разных направлений. Именно такой сценарий не удалось исключить авторам нового масштабного обзора. Проверить его предсказания астрономы смогут уже в ближайшие годы.
Ученые впервые на молекулярном уровне доказали, что обычная вода одновременно состоит из двух разных жидких состояний — более плотного и менее плотного, которые непрерывно сменяют друг друга. Раз молекулярная «двойственность» действительно существует, это подтверждает спорную 30-летнюю гипотезу. Новое открытие поможет, наконец, объяснить десятки «странных» физических аномалий воды, включая ее расширение при замерзании и парадоксальное изменение вязкости под давлением.

Вы попытались написать запрещенную фразу или вас забанили за частые нарушения.
Понятно
Что-то в вашем комментарии показалось подозрительным, поэтому перед публикацией он пройдет модерацию.
Понятно
Из-за нарушений правил сайта на ваш аккаунт были наложены ограничения. Если это ошибка, напишите нам.
Понятно
Наши фильтры обнаружили в ваших действиях признаки накрутки. Отдохните немного и вернитесь к нам позже.
Понятно







Мы скоро изучим заявку и свяжемся с Вами по указанной почте в случае положительного исхода. Спасибо за интерес к проекту.
Понятно
Последние комментарии