Инженеры Google описали ключевой изъян машинного обучения, приводящий к ошибкам ИИ
Тема искусственного интеллекта в последние годы стала невероятно популярной. Однако, несмотря на все достижения в этой области, ИИ по-прежнему чаще человека ошибается практически в любом классе задач. Специалисты Google сформулировали один из ключевых недостатков важнейшего компонента создания искусственного интеллекта — машинного обучения — и предложили способ его компенсации.
Научная работа опубликована на портале arXiv. В ней описано понятие недостаточной детализации (underspecification) в машинном обучении (machine learning). Авторы указывают на то, как в привычном процессе обучения нейросетевых алгоритмов слишком часто возникают неочевидные поначалу аномалии. В результате обученный таким образом алгоритм будет выдавать непредсказуемые или ошибочные выводы.
По мнению команды специалистов из Google, проблема в следующем. Во время обучения алгоритма на некоем наборе данных искусственный интеллект может сделать не совсем то обобщение, которое считают необходимым или эффективным его создатели. И сам по себе этот факт не является чем-то негативным, наоборот — в этом и есть «сила» нейросетей. Но, тренируя алгоритм, программисты не учитывают и далеко не всегда могут знать, что именно он выбрал в качестве дополнительных критериев. В итоге, классифицируя результаты как точные и неточные, человек обучает ИИ не совсем тому, чему хотел.
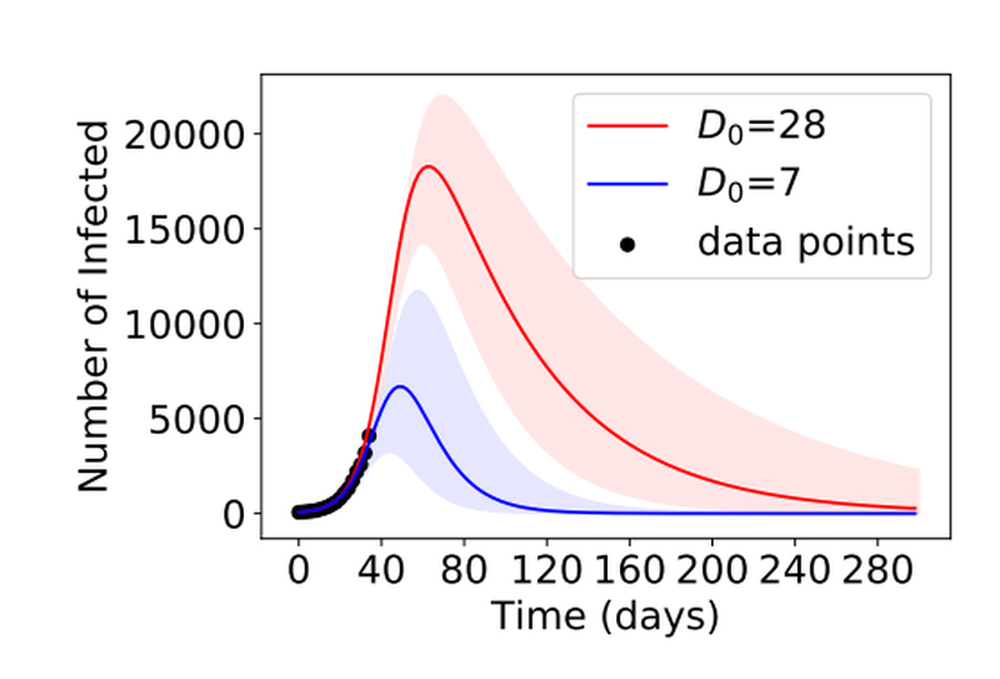
Результатом подобного обучения могут стать непредсказуемые ошибки. Например, в эпидемиологии есть математическая модель, описывающая течение эпидемии. Она строится на ключевых параметрах: коэффициенте распространения инфекции (R0) и продолжительности времени, пока заболевший заразен (D). Теоретически даже на ранних стадиях пандемии можно проанализировать эти данные по нескольким случаям и предсказать ее ход. Это крайне важно для властей и медиков, которые будут иметь понимание, когда переполнятся больницы и в какой момент и как нужно реагировать на статистику.
Однако на практике обученный по массивам медицинских данных искусственный интеллект может выдавать разные предсказания. И выбор из них реалистичного — нетривиальная задача. Дело в том, что во время обучения алгоритм будет учитывать множество побочных параметров. Так же делают и люди, но они могут объяснить свои решения, а ИИ — нет. Таким образом, необходимо еще на стадии создания алгоритма и его обучения учитывать все больше параметров. В этот момент появляется второе ключевое ограничение.
Подобных второстепенных параметров может быть огромное количество, и далеко не все из них будут так же важны для человека, как для нейросети. Фактически предсказать только по результату (прогнозу) модели, на основании каких второстепенных факторов была достигнута нужная точность, невозможно. И тем более нельзя сходу оценить, как именно изменится работа алгоритма при других масштабах поступающих данных. Свои соображения авторы описываемой работы наглядно и подробно иллюстрируют четырьмя примерами, в которых ИИ либо традиционно считается более точным, чем человек, либо его использование предполагается наиболее перспективным. Речь о компьютерном зрении, распознавании медицинских изображений и речи , а также медицинских предсказаниях на основе статистики.
Однако не все так ужасно. Авторы работы предлагают методику стрессового тестирования искусственного интеллекта. По их мнению, можно ввести в процесс машинного обучения обязательные стресс-тесты на специально подготовленных данных. Они могут быть нарочно выходящими за рамки моделей или хорошо изученными экстремальными примерами из реальной жизни. В любом случае с их помощью будут сразу обнаружены основные аномалии алгоритма.
Несомненно, озвученные сотрудниками Google идеи не являются революционными и зачастую используются на практике. Но они еще не стали стандартом даже в самых критичных для нас областях применения ИИ. И, конечно, для многих профессионалов вышеописанная работа может выглядеть простой и очевидной. Тем не менее в ней от элементарных моделей до сложнейших симуляций показано влияние недостаточной детализации на результат. Кроме того, авторы работы собрали воедино идеи и выводы из колоссального количества публикаций на смежные темы. Это позволяет назвать ее отличным промежуточным итогом в развитии современных наработок в области ИИ.
 Telegram
Telegram  Дзен
Дзен Сексуальная удовлетворенность женщин оказалась намного сильнее связана не с тем, насколько легко достигается оргазм, а с тем, чтобы это происходило именно с партнером. К такому выводу пришли исследователи, проанализировавшие данные почти 28 тысяч пользовательниц приложения Flo.
Ученые выяснили, что младенцы древних предков человека рождались столь же несамостоятельными, как современные новорожденные. Изучение древних черепов показало, что уход за практически беспомощным потомством имел место сотни тысяч лет назад.
Немецкие ученые выяснили, как золото формируется в недрах Земли. Анализ пород со дна океана показал, что глубоко под подводными вулканами работает природная «фабрика», концентрирующая драгоценный металл в поднимающейся магме.
Американские ученые установили, что привычка регулярно пить кофе значительно снижает риск развития цирроза, рака печени и печеночных патологий. Новые данные помогают объяснить биохимические механизмы, стоящие за защитным эффектом этого напитка.
Сексуальная удовлетворенность женщин оказалась намного сильнее связана не с тем, насколько легко достигается оргазм, а с тем, чтобы это происходило именно с партнером. К такому выводу пришли исследователи, проанализировавшие данные почти 28 тысяч пользовательниц приложения Flo.
Ученые из Сколтеха (группа ВЭБ.РФ) и их коллеги из Университета ИТМО и НИУ ВШЭ впервые продемонстрировали прямую электрическую накачку поляритонного лазера на основе галогенидного перовскитного микрокристалла, полученного из раствора. Результаты исследования представляют собой решение давней проблемы физики полупроводников и оптоэлектроники, которая десятилетиями оставалась препятствием на пути к решению технологической задачи: создать недорогие неэпитаксиальные лазерные диоды, работающие под непрерывным электрическим током. Такие устройства найдут применение в оптических сенсорах и спектроскопии, высокоскоростных вычислениях и энергоэффективных нейроморфных компьютерах.
Долгое время считалось, что до прихода европейцев тропические леса Амазонии были заселены сравнительно плохо. Однако выяснилось, что плотная растительность скрывает большинство следов древних обществ. С помощью воздушного лазерного сканирования ученые обнаружили сотни неизвестных земляных сооружений и предположили, что около двух тысяч лет назад население юго-западной части Амазонии могло достигать трех миллионов человек.
Видеосервисы стали неотъемлемой частью жизни россиян. В 2026 году охваты большинства платформ продолжают расти, в том числе YouTube.
Очереди на заправках стали привычным явлением в России, а на фоне информационного вакуума от властей о конкретных показателях производства бензина в июне население вынуждено ориентироваться на слухи. Все это выглядит довольно странно, но есть нюанс: скорее всего, кризис уже начинает выдыхаться. Как именно мы это выяснили?

Вы попытались написать запрещенную фразу или вас забанили за частые нарушения.
Понятно
Что-то в вашем комментарии показалось подозрительным, поэтому перед публикацией он пройдет модерацию.
Понятно
Из-за нарушений правил сайта на ваш аккаунт были наложены ограничения. Если это ошибка, напишите нам.
Понятно
Наши фильтры обнаружили в ваших действиях признаки накрутки. Отдохните немного и вернитесь к нам позже.
Понятно







Мы скоро изучим заявку и свяжемся с Вами по указанной почте в случае положительного исхода. Спасибо за интерес к проекту.
Понятно
Последние комментарии