Нейросеть научили артикуляции Барака Обамы
Специалисты из Вашингтонского университета разработали компьютерный алгоритм, который позволяет адаптировать мимику изображенного человека к стороннему аудиоряду.
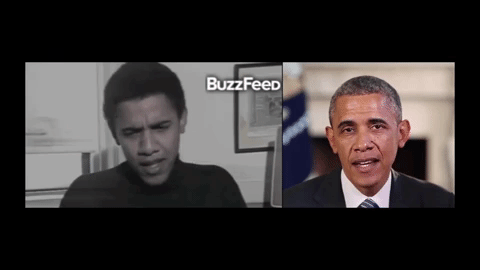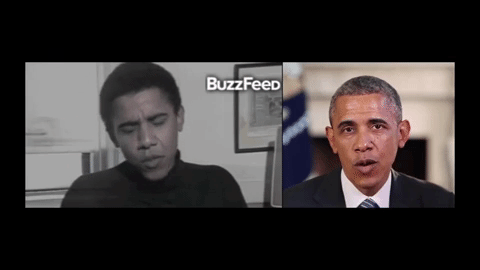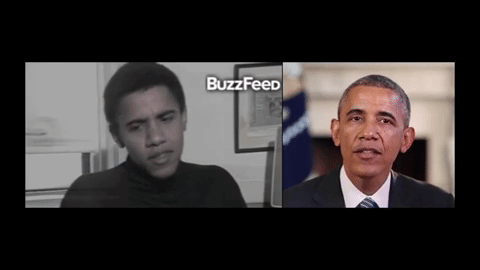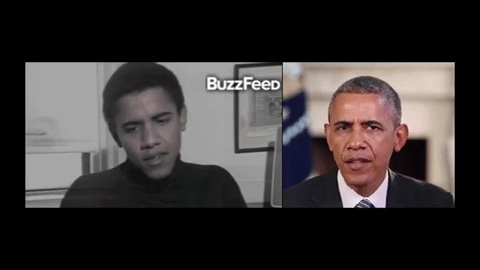
Синхронизация видео- и аудиодорожек важна во многих областях: политике, бизнесе и искусстве. Так, видеоконференции нередко сопровождаются задержкой сигнала, в результате чего речь изображенного человека не соответствует артикуляции. Искусственная адаптация фонем к микродвижениям, кроме того, актуальна для киноиндустрии: она могла бы упростить озвучивание персонажей. Ранее французские ученые представили алгоритм с обратной функцией — для воспроизведения голоса по положению губ. Системы, способные монтировать аудиоряд в видеоролик, также создаются, однако до сих пор при их разработке использовались только видео, записанные в лабораторных условиях.
Авторы новой статьи на этапе проектирования алгоритма задействовали записи естественной речи бывшего президента США Барака Обамы. На первом этапе они с помощью рекуррентной нейросети описали артикуляционную мимику политика на основе фонем из четырех его видеообращений к гражданам страны. Затем с помощью полученной модели ученые нарисовали трехмерную маску (с нейтральным выражением) экс-главы государства и обучили систему совмещать изображение с ней и произвольным аудиорядом. Для повышения реалистичности команда также учитывала характерные для бывшего президента движения головы и общую мимику. Тренировка искусственной нейросети продолжалась от 3 трех минут до 14 часов.

Тесты показали, что точность наложения коррелирует с продолжительностью обучения. Так, максимального результата алгоритму удалось достичь после семи и более часов. Авторы отмечают, что последний использовал в качестве базовых единиц сравнительно простые комбинации из не более чем пяти фонем (пентафонов), поскольку вероятность встретить в разных видео более сложные одинаковые последовательности звуков чрезвычайно мала. Эффективность адаптации видеоряда исходя из комбинаций при этом составила от 4,9 процента для пентафонов до 82,9–99,9 процента для три- и дифонов соответственно. Для сравнения, среднее слово в английском языке содержит 3,9 фонемы.
В рамках демонстрации исследователи испытали технологию на четырех других видеозаписях, сделанных во время интервью Обамы актеру Стиву Харви, ток-шоу The View, журналу Harvard Law Review (в 1990 году), а также выступления пародиста. Нейросеть хорошо адаптировала аудиодорожки к видеообращениям. Дополнительно разработку сравнили с аналогичным сервисом Face2face, который весной 2016 года представили специалисты из Стэнфордского университета, Общества Макса Планка и Университета Эрлангена — Нюрнберга. По мнению ученых, новая система позволяет повысить реалистичность целевой записи. При этом, в отличие от Face2face, она может обучаться только по аудиоряду.
Статья опубликована на сайте Вашингтонского университета.
Ранее американский программист создал искусственную нейросеть для превращения мужских лиц на снимках в женские и наоборот.
 Telegram
Telegram  Дзен
Дзен Американские ученые установили, что привычка регулярно пить кофе значительно снижает риск развития цирроза, рака печени и печеночных патологий. Новые данные помогают объяснить биохимические механизмы, стоящие за защитным эффектом этого напитка.
Бывшие сотрудники NASA констатировали, что последнее видео испытаний крупнейшего космического корабля в истории снова показало проблемы и ограничения его теплового щита. С их точки зрения, любая из существующих технологий такого типа слишком сложна для реализации замысла Илона Маска о быстрой и безремонтной многоразовости Starship.
Ученые из Сколтеха (группа ВЭБ.РФ) и их коллеги из Университета ИТМО и НИУ ВШЭ впервые продемонстрировали прямую электрическую накачку поляритонного лазера на основе галогенидного перовскитного микрокристалла, полученного из раствора. Результаты исследования представляют собой решение давней проблемы физики полупроводников и оптоэлектроники, которая десятилетиями оставалась препятствием на пути к решению технологической задачи: создать недорогие неэпитаксиальные лазерные диоды, работающие под непрерывным электрическим током. Такие устройства найдут применение в оптических сенсорах и спектроскопии, высокоскоростных вычислениях и энергоэффективных нейроморфных компьютерах.
Бывшие сотрудники NASA констатировали, что последнее видео испытаний крупнейшего космического корабля в истории снова показало проблемы и ограничения его теплового щита. С их точки зрения, любая из существующих технологий такого типа слишком сложна для реализации замысла Илона Маска о быстрой и безремонтной многоразовости Starship.
Правильно подобранные звуковые последовательности способны не только стимулировать рост растений, но и влиять на их урожайность. К такому выводу пришли авторы нового исследования. Они разработали технологию, которая позволяет воздействовать на процессы развития растений через акустические сигналы без использования генной инженерии или химикатов. В экспериментах добились повышения урожайности мяты, сои, болгарского перца и конопли.
Американские ученые установили, что привычка регулярно пить кофе значительно снижает риск развития цирроза, рака печени и печеночных патологий. Новые данные помогают объяснить биохимические механизмы, стоящие за защитным эффектом этого напитка.
Видеосервисы стали неотъемлемой частью жизни россиян. В 2026 году охваты большинства платформ продолжают расти, в том числе YouTube.
Очереди на заправках стали привычным явлением в России, а на фоне информационного вакуума от властей о конкретных показателях производства бензина в июне население вынуждено ориентироваться на слухи. Все это выглядит довольно странно, но есть нюанс: скорее всего, кризис уже начинает выдыхаться. Как именно мы это выяснили?
Древнеримские инженеры проложили колоссальную сеть дорог через Европу, Северную Африку и Ближний Восток, многие участки которой до сих пор поражают безупречной прямолинейностью. Секрет строительства заключался в использовании трех особых геодезических инструментов, с помощью которых разбивали местность на ровные отрезки и размечали трассы.

Вы попытались написать запрещенную фразу или вас забанили за частые нарушения.
Понятно
Что-то в вашем комментарии показалось подозрительным, поэтому перед публикацией он пройдет модерацию.
Понятно
Из-за нарушений правил сайта на ваш аккаунт были наложены ограничения. Если это ошибка, напишите нам.
Понятно
Наши фильтры обнаружили в ваших действиях признаки накрутки. Отдохните немного и вернитесь к нам позже.
Понятно






Мы скоро изучим заявку и свяжемся с Вами по указанной почте в случае положительного исхода. Спасибо за интерес к проекту.
Понятно
Последние комментарии