#нейросети
В последние месяцы участились сообщения о том, что технологические компании во время тестирований теряют контроль над искусственным интеллектом. Судя по всему, ИИ-модели OpenAI уже начали делиться со своими будущими версиями способами, как обойти ограничения.
Компания Anthropic решила проверить, насколько ИИ-помощник Claude готов подчиняться руководству компании. В итоге модель ослушалась генерального директора компании Дарио Амодеи.

Исследователи «Яндекса» предложили способ решить проблему «катастрофического забывания» при обновлении слов-триггеров для умных устройств. Гаджеты смогут узнавать новые голосовые команды, продолжая распознавать уже известные. Исследование с описанием подхода авторы представят на международной конференции Interspeech 2026, которая пройдет с 27 сентября по 1 октября в Сиднее.

Как нейросети меняют рынок дизайна, почему брендинг превращается в систему данных и какие навыки будут определять профессию дизайнера в ближайшие годы — рассказывает кандидат технических наук, заведующий кафедрой автоматизированного проектирования и дизайна НИТУ МИСИС Евгений Коржов.

Большинство ИИ-моделей отказываются помогать с созданием программ-вымогателей. Ситуация меняется, если правильно сформулировать запрос. Специалисты по кибербезопасности пришли к выводу, что модели вроде DeepSeek вполне могут помочь с созданием вредоносных программ.
Мошенники уже давно продают в интернете семена несуществующих экзотических цветов. Теперь с помощью искусственного интеллекта они генерируют удивительные цветы, напоминающие бабочек или птиц.

Сегодня перед ИИ-индустрией стоят важные задачи: как эффективнее использовать вычислительные ресурсы, ускорить обучение моделей, работать со сложными данными и снизить зависимость от дорогостоящей ручной разметки? Этим вопросам посвящена серия научных работ, которые исследователи и инженеры «Яндекса» представили на International Conference on Machine Learning. Все эти исследования вошли в основную программу конференции.

Нейроморфные вычисления — это попытка скопировать принцип работы мозга: не последовательно выполнять команды, как обычный процессор, а обрабатывать информацию параллельно, через сеть взаимосвязанных «нейронов», которые активируются в зависимости от поступающих сигналов. Эта идея существует уже несколько десятилетий, но до недавнего времени ее реализовывали на обычной электронной элементной базе. Исследователи из МФТИ провели обширный обзор, в котором систематизировали последние достижения в области фотонных нейроморфных вычислений.

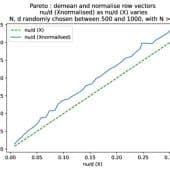
Новый метод оценки сложности данных, формируемых нейронными сетями, позволяет лучше понять принципы их обучения. В работе представлена размерность Патнаика-Пирсона как мера внутренней размерности данных, связывающая современные теории обучения нейронных сетей и поведение трансформеров.
Искусственный интеллект все сильнее влияет на экономику, в том числе Соединенных Штатов. Однако большинство американцев не испытывают особого оптимизма по поводу его долгосрочного влияния на страну.

В начале марта 2026 года, когда США напали на Иран, Naked Science пришел к выводу, что Штаты не могут победить. 18 июня стороны подписали меморандум, который выглядит капитуляцией американцев. Даже более сильной, чем во время кризиса с захватом их посольства в Тегеране в 1981 году. Несмотря на все попытки Трампа сделать вид, что он готов не выполнять меморандум, у него, по сути, нет выбора. Как мы увидим ниже, ему придется. За счет чего произошла эта невероятная победа?

Преподаватель из МФТИ показал, что привычные тексты на иностранном языке с прилагающимся набором упражнений могут уступить место мультимедийному генеративному продукту — графическому нейророману.

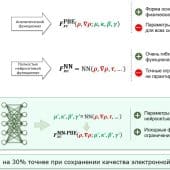
Ученые усовершенствовали инструмент для моделирования химических реакций и предсказания свойств молекул, который использует нейросети для тонкой подстройки параметров. В отличие от полностью нейросетевых подходов, новый алгоритм не нарушает фундаментальные законы физики и снижает ошибку в расчетах энергии химических реакций почти на 26%. Благодаря этому он позволяет точнее описывать поведение электронов в сложных химических системах, что необходимо для предсказания их свойств, например при разработке новых лекарств, катализаторов и материалов.
Компания Anthropic — разработчик нейросети Claude — призвала другие компании замедлить или временно приостановить разработку передовых систем искусственного интеллекта. По мнению представителей Anthropic, ИИ-модели уже демонстрируют признаки того, что в будущем они смогут выйти из-под контроля людей.

Технологические компании то и дело сообщают об успехах своих ИИ-моделей в решении математических задач, которые считались крайне сложными. Однако математики со всего мира призвали правительства не верить в шумиху вокруг искусственного интеллекта.

Разработка поможет уберечь суда от экстремальных явлений погоды и обеспечит безопасную работу портов и нефтегазовых платформ в северных морях. При тестировании ИИ-модель показала отклонение менее трех процентов от эталонных данных по числу выявленных вихрей.
Расходы бизнеса на искусственный интеллект иногда выходят за рамки запланированного бюджета. Например, некая компания случайно потратила 500 миллионов долларов на Claude AI за один месяц.

Исследователи обнаружили, что большие языковые модели (LLM) избегают религиозных трактовок, при этом особо негативное отношение они проявляют к Свидетелям Иеговы*. В большинстве случаев нейросети предпочитают светское, рационально-научное мышление.

Последние годы авторы активно используют искусственный интеллект для поиска литературы и редактирования текста, но идея поручить ему экспертную оценку научных статей вызывает много споров. На первый взгляд, машинное рецензирование заметно экономит время и упрощает процесс публикации, однако в то же время оно несет риски для качества науки, конфиденциальности и академической культуры.



Вы попытались написать запрещенную фразу или вас забанили за частые нарушения.
Понятно
Что-то в вашем комментарии показалось подозрительным, поэтому перед публикацией он пройдет модерацию.
Понятно
Из-за нарушений правил сайта на ваш аккаунт были наложены ограничения. Если это ошибка, напишите нам.
Понятно
Наши фильтры обнаружили в ваших действиях признаки накрутки. Отдохните немного и вернитесь к нам позже.
Понятно







Мы скоро изучим заявку и свяжемся с Вами по указанной почте в случае положительного исхода. Спасибо за интерес к проекту.
Понятно
Последние комментарии