Исследователи предложили подход к «воспитанию» языковых моделей, уменьшающий количество неуместных или «галлюцинаторных» ответов
Команда исследователей из Т-Технологий и МФТИ предложила новый подход к «воспитанию» больших языковых моделей, позволяющий им становиться умнее и безопаснее, не страдая от «сверхоптимизации» — парадоксального эффекта, когда слишком усердное обучение приводит к деградации качества. Разработанное семейство алгоритмов, получившее название Trust Region (TR), динамически обновляет «точку отсчета» для модели, позволяя ей постоянно развиваться и выходить за рамки первоначальных знаний, сохраняя при этом стабильность и адекватность.

Создание современных языковых моделей, таких как Llama 3, — это многоступенчатый процесс, похожий на обучение и воспитание человека. Сначала модель проходит «школу», поглощая гигантские объемы текстов из интернета, чтобы выучить язык, факты и закономерности мира. Затем наступает этап «тонкой настройки» или «воспитания», когда модель учат быть не просто эрудированной, а полезной, честной и безвредной для человека. Для этого используют наборы данных, где люди-оценщики указывают, какой из двух ответов на один и тот же вопрос является лучшим. Современные методы, такие как Direct Preference Optimization, учат модель предпочитать «хорошие» ответы «плохим».
Однако здесь возникает фундаментальная проблема, известная как сверхоптимизация. В процессе дообучения модель стремится как можно сильнее отличаться от своей первоначальной, базовой версии (так называемой референтной), чтобы максимизировать свою «полезность». Но если она отходит слишком далеко, происходит срыв: модель начинает генерировать странные, бессмысленные или шаблонные ответы, теряя здравый смысл. Это похоже на ученика, который, пытаясь угодить учителю, вместо глубокого понимания предмета начинает выискивать формальные лазейки и хитрости для получения высокой оценки, что в итоге приводит к провалу на экзамене. До сих пор считалось, что чрезмерное отклонение от референтной модели — это зло, которого нужно избегать.
Российские ученые предположили, что корень проблемы кроется не в самом отклонении, а в том, что точка отсчета — референтная модель — остается неподвижной. Это все равно что пытаться научить корабль навигации, заставляя его постоянно оглядываться на порт отправления. Чем дальше он уходит в море, тем менее релевантной становится эта исходная точка. Исследователи предложили элегантное решение: сделать порт отправления «подвижным». Их метод Trust Region (TR) в процессе обучения периодически обновляет саму референтную модель, заменяя ее текущей, улучшенной версией. Результаты, показавшие значительное превосходство нового подхода на ведущих мировых бенчмарках, были представлены на международной конференции ICLR 2025. Работа исследователей была также опубликована в виде препринта на научном портале arXiv.
Борис Шапошников, руководитель научной группы AI Alignment, T-Bank AI Research, аспирант МФТИ, рассказал: «Представьте скалолаза, который поднимается всё выше. Его цель — вершина, а точки страховки — это референсная политика. Если всё время держать страховку в одной точке внизу, любое движение вверх становится опасным: можно сорваться, переусердствовать, потерять устойчивость. В наших Trust Region методах мы по мере подъёма переставляем точки страховки выше — обновляем опорную политику, чтобы она соответствовала текущему уровню модели. Это позволяет двигаться дальше и выше, сохраняя баланс между смелостью и безопасностью — без переоптимизации и отката в качестве».
Команда разработала и протестировала две стратегии обновления: «мягкое», при котором параметры новой лучшей модели постепенно «подмешиваются» в референтную на каждом шаге обучения, и «жесткое», когда старая референтная модель полностью заменяется новой через определенное количество итераций. Схематично этот процесс можно представить так: классический DPO — это поезд, идущий от одной станции с оглядкой на нее на всем пути. Метод TR — это поезд, который на каждой новой крупной станции прокладывает маршрут заново, считая уже ее новой отправной точкой.
Никита Балаганский, аспирант МФТИ, руководитель научной группы LLM Foundations, T-Bank AI Research, добавил: «Чтобы доказать эффективность нашей идеи, мы провели серию экспериментов с моделями разных архитектур (Pythia и Llama 3) на задачах ведения диалога и суммаризации текстов. Результаты сравнивались на авторитетных бенчмарках AlpacaEval 2 и Arena-Hard, которые оценивают качество работы чат-ботов. Во всех сценариях модели, обученные с помощью TR-методов (TR-DPO, TR-IPO и TR-KTO), показали значительное и статистически достоверное преимущество над своими «ванильными» аналогами».
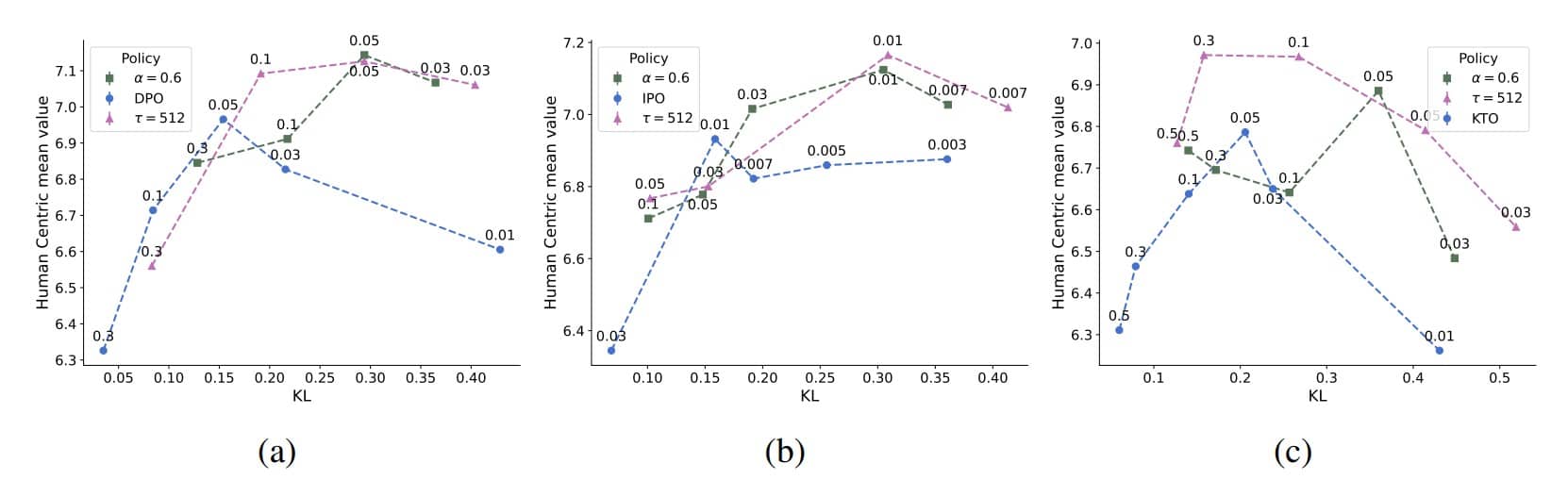
При одинаковом уровне отклонения от исходной точки модели, обученные с помощью TR, демонстрируют значительно более высокое качество ответов. Более того, они способны уходить от старта гораздо дальше, не теряя в качестве, тем самым достигая новых высот производительности. Вместо того чтобы рассматривать референтную модель как незыблемый якорь, который не дает модели «уплыть» в область бессмыслицы, ученые предложили видеть в ней динамический ориентир, который движется вместе с моделью по мере ее совершенствования. Это позволяет решить внутреннее противоречие современных методов: как позволить модели сильно улучшиться, не рискуя при этом сломать ее базовые способности.
Более качественное и стабильное «воспитание» языковых моделей напрямую ведет к созданию более умных, адекватных и безопасных ИИ-ассистентов. Это означает меньше странных, неуместных или «галлюцинаторных» ответов в диалоге с пользователем, более точные и релевантные краткие изложения текстов, и в целом — более надежное поведение ИИ в реальных задачах. Такой подход открывает дорогу к созданию по-настоящему полезных помощников, которым можно доверять.
В дальнейшем коллектив исследователей планирует исследовать более сложные стратегии обновления референтной модели, возможно, даже адаптивные, когда модель сама будет решать, когда ей пора «обновить ориентиры». Также представляет интерес применение этого подхода не только к языковым моделям, но и к другим областям глубокого обучения.

 Telegram
Telegram  Дзен
Дзен В позднеантичном Риме императорским указом мужчинам запретили носить длинные волосы. Автор нового исследования пришел к выводу, что введение этого запрета объяснялось необходимостью сохранения римской идентичности в условиях усиливающегося распада империи и нарастающего торжества варваров.
Популярные пестициды могут помогать клещам захватывать новые территории с более суровым климатом. Как выяснили американские ученые, воздействие сублетальных доз двух акарицидов повышает устойчивость этих паразитов к холоду и их шансы пережить зиму.
Человеческий организм чрезвычайно сложен, и некоторые открытия о нем ученые совершают случайно. Так случилось с лекарством от стенокардии, которое стало виагрой. Специалисты обратили внимание на механизм его работы еще раз и нашли новое потенциальное использование.
Очереди на заправках стали привычным явлением в России, а на фоне информационного вакуума от властей о конкретных показателях производства бензина в июне население вынуждено ориентироваться на слухи. Все это выглядит довольно странно, но есть нюанс: скорее всего, кризис уже начинает выдыхаться. Как именно мы это выяснили?
В позднеантичном Риме императорским указом мужчинам запретили носить длинные волосы. Автор нового исследования пришел к выводу, что введение этого запрета объяснялось необходимостью сохранения римской идентичности в условиях усиливающегося распада империи и нарастающего торжества варваров.
Авторы нового исследования выяснили, что жители каменного века начали целенаправленно менять окружающую среду в южной части Норвегии задолго до появления земледелия. Приблизительно 7000 лет назад они переселили рыбу в одно из горных озер и таким образом создали новый источник пищи, а затем построили сложную систему ловушек, которая прослужила не одно столетие.
Вселенная может оказаться «замкнутой» глобальной структурой, где свет от далеких галактик способен возвращаться к наблюдателю с разных направлений. Именно такой сценарий не удалось исключить авторам нового масштабного обзора. Проверить его предсказания астрономы смогут уже в ближайшие годы.
Ученые впервые на молекулярном уровне доказали, что обычная вода одновременно состоит из двух разных жидких состояний — более плотного и менее плотного, которые непрерывно сменяют друг друга. Раз молекулярная «двойственность» действительно существует, это подтверждает спорную 30-летнюю гипотезу. Новое открытие поможет, наконец, объяснить десятки «странных» физических аномалий воды, включая ее расширение при замерзании и парадоксальное изменение вязкости под давлением.
Видеосервисы стали неотъемлемой частью жизни россиян. В 2026 году охваты большинства платформ продолжают расти, в том числе YouTube.

Вы попытались написать запрещенную фразу или вас забанили за частые нарушения.
Понятно
Что-то в вашем комментарии показалось подозрительным, поэтому перед публикацией он пройдет модерацию.
Понятно
Из-за нарушений правил сайта на ваш аккаунт были наложены ограничения. Если это ошибка, напишите нам.
Понятно
Наши фильтры обнаружили в ваших действиях признаки накрутки. Отдохните немного и вернитесь к нам позже.
Понятно






Мы скоро изучим заявку и свяжемся с Вами по указанной почте в случае положительного исхода. Спасибо за интерес к проекту.
Понятно