Исследователи «Яндекса» представили способ повысить качество работы рекомендательных систем
Исследователи рекомендательных технологий «Яндекса» нашли способ, как повысить качество работы рекомендательных систем, чтобы они лучше понимали предпочтения пользователей, например, в товарах или контенте, и составляли более точные рекомендации. Для этого исследователи внедрили дополнительную корректировку в процесс обучения таких моделей.
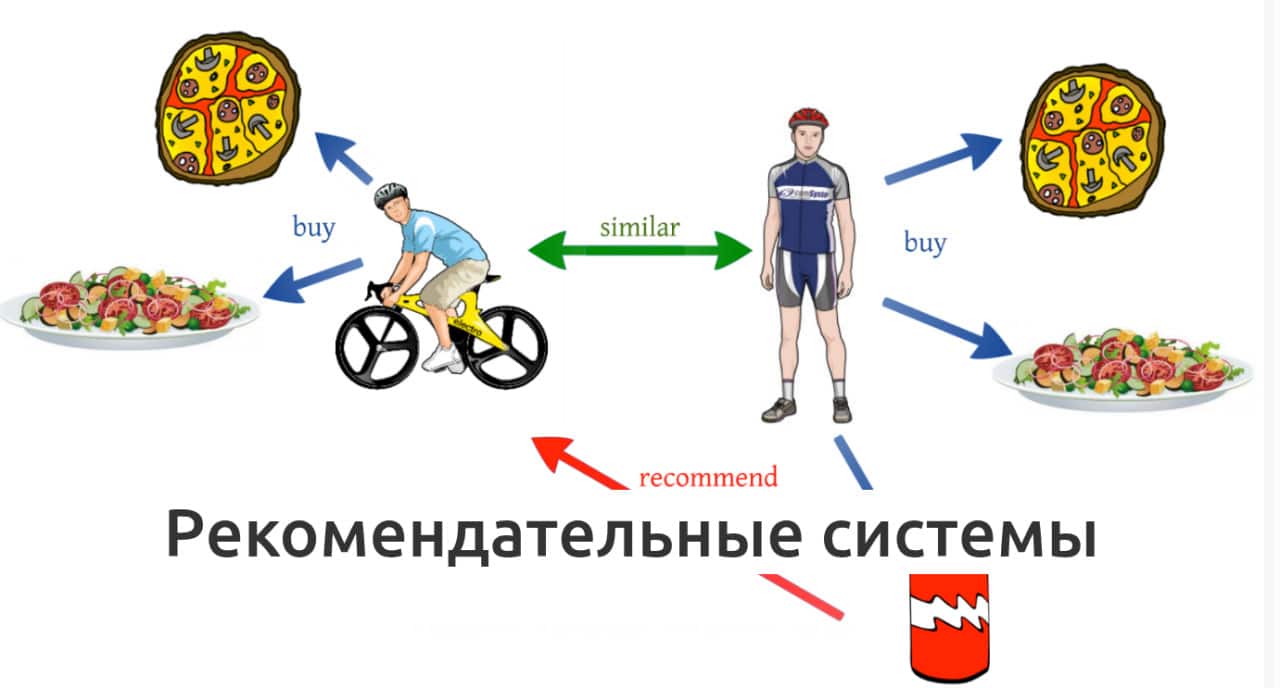
Внутреннее тестирование «Яндекса» показало, что новый подход позволяет повысить точность рекомендаций моделей в среднем на семь процентов по показателям качества ранжирования. «Яндекс» планирует использовать метод при обучении рекомендательных моделей собственных сервисов, в частности «Маркета». Метод будет полезен и другим компаниям, а также независимым разработчикам, работающим с рекомендательными системами в любой сфере — будь то соцсеть, интернет-магазин или стриминговый сервис.
О новом методе исследователи «Яндекса» рассказали в научной статье, которая была принята на ACM RecSys 2025. Это главная ежегодная международная конференция по рекомендательным системам, которая в этом году пройдет в девятнадцатый раз в Чехии. На конференцию также приняты работы крупнейших мировых технологических компаний — Amazon, Google и других.
Неточности при обучении рекомендательных систем
Рекомендательные системы обычно работают с миллионами объектов — текстами, аудио, видео, товарами. Это требует больших вычислительных ресурсов. Но сначала модель нужно обучить также на миллионах примеров, и для этого тоже необходимо много ресурсов. Чтобы сделать этот процесс менее ресурсоемким, во всем мире используют разные методы, которые заменяют сложные расчеты на более простые. Один из таких методов — sampled softmax, или алгоритм выборочного сэмплирования.
Его суть в том, что систему обучают различать предпочтения людей путем сравнения реализованных действий, которые пользователи совершили по отношению к конкретному объекту (положительные примеры), с нереализованными действиями, которых они не совершали относительно того же объекта (отрицательные примеры). В качестве объекта, например, может выступать определенный товар, тогда положительный пример — это добавление в корзину, а отрицательный — просмотр на сайте без добавления.
Обучение системы строится на том, что ей показывают положительный пример и отрицательные, — и благодаря этому модель начинает отличать одно от другого. Но можно показать ей миллионы отрицательных примеров из обучающего каталога, а можно лишь несколько случайно выбранных — в этом и заключается преимущество метода sampled softmax, которое позволяет экономить вычислительные ресурсы. Однако этот метод может привести к некачественному обучению из-за некорректного учета вероятностей — актуальна ли для пользователя рекомендация или нет. В результате модель будет давать неверные рекомендации.
Решение с помощью новой формулы
Для корректной работы метода требуется использовать обновленную формулу пересчета вероятностей того, что пользователь заинтересуется определенным товаром или контентом, — LogQ. Главная математическая трудность была в том, что существующие методы предполагают одинаковые правила отбора для всех примеров, а на практике положительные и отрицательные примеры попадают в данные по-разному. Из-за этого стандартные формулы начинают систематически искажать оценки, и требовалось специально скорректировать пересчет вероятностей, чтобы сделать модель объективнее.
Благодаря формуле модель при обучении начинает понимать, что реальные действия пользователя выбираются не случайным образом и явно задаются ей как положительные примеры, а остальные примеры — отрицательные и выбраны случайно. Это позволяет уменьшить смещения в оценках со стороны модели, то есть искажения, влияющие на точность ее финальных рекомендаций. В результате модель лучше понимает предпочтения пользователей и, как следствие, дает им более подходящие рекомендации.
Компании и разработчики могут использовать новую формулу при обучении любой рекомендательной системы. Для этого им не придется менять архитектуру своих моделей.
 Telegram
Telegram  Дзен
Дзен Нейробиологи и специалисты по микробиологии выяснили, что нарушения в видовом составе кишечных бактерий (так называемый дисбиоз) и изменение уровня продуктов из жизнедеятельности могут ключевым образом влиять на уровень стресса, включая депрессию, тревожные состояния и посттравматическое стрессовое расстройство.
Правильно подобранные звуковые последовательности способны не только стимулировать рост растений, но и влиять на их урожайность. К такому выводу пришли авторы нового исследования. Они разработали технологию, которая позволяет воздействовать на процессы развития растений через акустические сигналы без использования генной инженерии или химикатов. В экспериментах добились повышения урожайности мяты, сои, болгарского перца и конопли.
Ученые впервые заглянули под поверхность Ио — самого вулканически активного тела Солнечной системы — без посадки космического аппарата. Данные зонда «Юнона» показали, что уже на небольшой глубине температура значительно выше, чем на поверхности, а внутреннее тепло спутника поднимается наружу.
Очереди на заправках стали привычным явлением в России, а на фоне информационного вакуума от властей о конкретных показателях производства бензина в июне население вынуждено ориентироваться на слухи. Все это выглядит довольно странно, но есть нюанс: скорее всего, кризис уже начинает выдыхаться. Как именно мы это выяснили?
В позднеантичном Риме императорским указом мужчинам запретили носить длинные волосы. Автор нового исследования пришел к выводу, что введение этого запрета объяснялось необходимостью сохранения римской идентичности в условиях усиливающегося распада империи и нарастающего торжества варваров.
Виктор Гловер, один из четырех человек, весной этого года пролетевших мимо Луны, выступил на конференции NASA и предложил резко изменить план высадки американцев на Луне в конце десятилетия. Он считает, что это позволит снизить риски для астронавтов-участников миссии.
Вселенная может оказаться «замкнутой» глобальной структурой, где свет от далеких галактик способен возвращаться к наблюдателю с разных направлений. Именно такой сценарий не удалось исключить авторам нового масштабного обзора. Проверить его предсказания астрономы смогут уже в ближайшие годы.
Ученые впервые на молекулярном уровне доказали, что обычная вода одновременно состоит из двух разных жидких состояний — более плотного и менее плотного, которые непрерывно сменяют друг друга. Раз молекулярная «двойственность» действительно существует, это подтверждает спорную 30-летнюю гипотезу. Новое открытие поможет, наконец, объяснить десятки «странных» физических аномалий воды, включая ее расширение при замерзании и парадоксальное изменение вязкости под давлением.
Видеосервисы стали неотъемлемой частью жизни россиян. В 2026 году охваты большинства платформ продолжают расти, в том числе YouTube.

Вы попытались написать запрещенную фразу или вас забанили за частые нарушения.
Понятно
Что-то в вашем комментарии показалось подозрительным, поэтому перед публикацией он пройдет модерацию.
Понятно
Из-за нарушений правил сайта на ваш аккаунт были наложены ограничения. Если это ошибка, напишите нам.
Понятно
Наши фильтры обнаружили в ваших действиях признаки накрутки. Отдохните немного и вернитесь к нам позже.
Понятно






Мы скоро изучим заявку и свяжемся с Вами по указанной почте в случае положительного исхода. Спасибо за интерес к проекту.
Понятно
Последние комментарии