Ученые выяснили, как отличить текст, написанный ИИ, от человеческого
Команда исследователей из Сколтеха, МФТИ, Института искусственного интеллекта AIRI и других научных центров разработала метод, позволяющий не просто отличать тексты, написанные человеком, от сгенерированных нейросетью, но и понимать, по каким именно признакам классификатор принимает решение о том, является ли текст генерацией или нет. Анализируя внутренние состояния глубоких слоев языковой модели, ученые смогли выделить и интерпретировать численные признаки, отвечающие за стилистику, сложность и «степень уверенности» текста.

Работа принята на конференцию Findings of ACL 2025 и опубликована в виде препринта на портале arXiv. Стремительное развитие больших языковых моделей (LLM), таких как ChatGPT, Gemma и LLaMA, привело к тому, что сгенерированные ими тексты наполнили интернет, учебники, учебные пособия и даже научные статьи. Возникла острая проблема: как отличить оригинальное человеческое творчество от продукта машины? Существующие системы детекции сгенерированного текста часто работают как «черные ящики»: они выдают вердикт «человек» или «ИИ», но не могут объяснить, на каких конкретно свойствах текста основано их решение. Такая непрозрачность ограничивает их гибкость и надежность: если детектор ошибается, то бывает очень сложно понять, почему именно он ошибся и как избежать такой ошибки в будущем.
Исследователи решили подойти к проблеме с другой стороны. Вместо того чтобы создавать еще один «черный ящик», они задались целью заглянуть «под капот» нейросети и превратить ее внутренние состояния в набор четких и интерпретируемых характеристик текста. Для этого они использовали известную технику — разреженные автокодировщики (Sparse Autoencoders, SAE). Если представить внутреннее состояние нейросети как сложный коктейль из тысяч смешанных сигналов, то SAE работает как высокоточный сепаратор, который раскладывает этот коктейль на более чистые, атомарные «ингредиенты», которые легче интерпретировать. Каждый такой признак отвечает за определенный аспект текста: например, за сложность предложений или использование специфической лексики.
Лаида Кушнарева, старший академический консультант в компании Huawei, прокомментировала: «Люди, регулярно имеющие дело с текстами, сгенерированными ChatGPT, зачастую могут распознать такой текст по характерным чертам — например, неуместно сухому и формальному языку, чрезмерно длинным и “водянистым” вступлениям перед переходом к сути, повторяющимся формулировкам одной и той же мысли и низкой информационной плотности в целом. Однако большинство популярных детекторов сгенерированных текстов не показывают, в какой степени в тексте присутствуют эти и другие понятные человеку особенности.
В отличие от них, наш детектор на основе SAE позволяет автоматически раскладывать тексты на “атомарные” числовые признаки, многие из которых поддаются интерпретации в терминах, понятных человеку. При этом детектор обходит все существующие решения на том наборе данных, который мы использовали. Кроме того, мы показали, что с помощью SAE можно обнаруживать и некоторые осознанные попытки скрыть факт генерации текста — например, преднамеренное добавление лишних пробелов, артиклей или нестандартных символов с целью запутать детекторы. Другими словами, данная техника позволяет автоматически разобрать текст “по косточкам” и принять решение, обоснованность которого может быть впоследствии проверена человеком на основе выявленных признаков и их интерпретации».
В ходе исследования ученые подавали на вход нейросети Gemma-2-2B различные примеры текстов и сохраняли внутренние состояния с глубоких слоев модели для каждого текста. Далее, они выделили из этих внутренних состояний тысячи “атомарных” признаков с помощью SAE. Используя эти признаки, они обучили классификатор для распознавания сгенерированных текстов и приступили к самой интересной части — интерпретации. Они выявили как «универсальные» признаки, характерные для многих генерирующих моделей, так и специфические, присущие отдельным семействам ИИ или определенным типам текста (например, научным статьям и отзывам). Так, в текстах на научные темы ИИ склонен к излишне сложным синтаксическим конструкциям, а в текстах на финансовую тематику — к необоснованным, многословным рассуждениям о простых фактах.
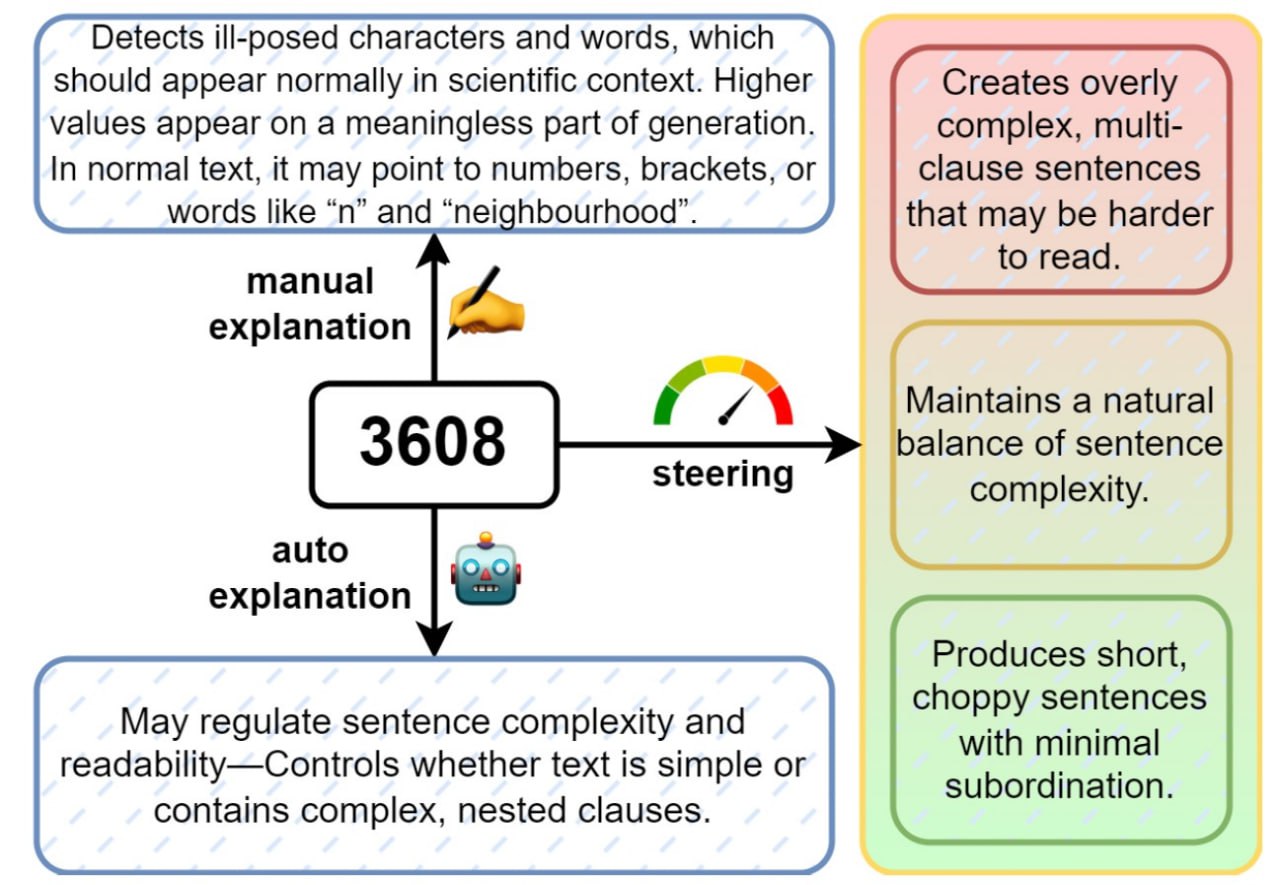
Интерпретации одного из самых «универсальных» признаков 3608, полезных для детектирования AI-текстов / ©
Kuznetsov, K. et al., ArXiv.org
Например, в работе показано, что «признак №3608 с 16-го слоя SAE» отвечает за синтаксическую сложность. Ученые обнаружили, что искусственное усиление этого признака в процессе генерации текста заставляет нейросеть создавать чрезмерно запутанные предложения, которые сложно читать. Наоборот, ослабление этого признака приводит к появлению коротких, «рубленых» фраз с минимальной связностью. Другой сильный признак, №4645, отвечает за степень уверенности текста, а №6587 — за многословные вступления и чрезмерно подробные объяснения.
Анастасия Вознюк, студентка МФТИ, добавила: «Помимо анализа того, на что конкретно модель обращает внимание при детекции, мы попробовали управлять моделью генерации. Признаки, которые мы определили ранее, можно усиливать или ослаблять, и в результате наблюдать что в некоторых случаях новый сгенерированный текст сильнее или, наоборот, слабее, характеризуется данным признаком. Например, при изменении признака определяющего уровень «академичности» языка текста, будет изменяться в соответствующую сторону и стилистика текста.
Результаты показывают, что если давать современным языковым моделям вроде ChatGPT стандартные запросы для генерации, то они с большой вероятностью генерируют текст с характерными чертами, который легко обнаруживается этим и другими детекторами. Однако исследователи предупреждают: если дать нейросети более персонализированное задание (например, попросить написать текст в каком-то необычном для нее стиле), эти характерные черты могут ослабнуть или даже исчезнуть, что может сделать задачу детекции значительно сложнее.
В исследовании был применен новый многогранный подход, который сочетает автоматическое выделение признаков, их ручную интерпретацию и экспериментальную проверку с помощью техники «управления» (steering). Это создает основу для разработки более интерпретируемых детекторов, которые смогут не просто выносить вердикт, но и предоставлять отчет о том, какие именно аномалии были найдены в тексте. Такие инструменты будут полезны для преподавателей, редакторов и исследователей дезинформации. В более широкой перспективе эта работа является важным шагом к демистификации искусственного интеллекта, позволяя нам лучше понимать, как нейросети «мыслят» и создают тексты.
Дальнейшие исследования будут направлены на применение этого метода к новым, более мощным языковым моделям и на изучение более сложных и трудноуловимых признаков, чтобы оставаться на шаг впереди тех, кто пытается использовать ИИ в недобросовестных целях, и при этом уменьшить вероятность ошибиться и несправедливо обвинить человека в том, что его текст был сгенерирован.

 Telegram
Telegram  Дзен
Дзен Ученые РГУ нефти и газа (НИУ) имени И. М. Губкина разработали синтетическое масло для газопоршневых двигателей, позволяющее снизить расход топливного метана на семь процентов. Продукт разработан в целях импортозамещения в сфере энергетики. Разработка открывает новые возможности распределенной энергетики на Крайнем Севере, Дальнем Востоке и других территориях без центральных сетей.
Археологи часто находят красивые прозрачные кристаллы на стоянках древних людей, живших почти 800 тысяч лет назад. Самое странное, что наши предки не делали из них наконечники для стрел или бусы, а, похоже, просто повсюду носили с собой и бережно складывали в кучи. Испанские ученые нашли объяснение этой странной привычке, понаблюдав за ближайшими родственниками человека — шимпанзе.
Большой коллектив ученых из Специальной астрофизической обсерватории РАН (п. Нижний Архыз), Астрокосмического центра ФИАН, Крымской астрофизической обсерватории РАН, Санкт-Петербургского государственного университета и МФТИ с коллегами впервые провел комплексный многоволновой анализ переменности блазара Тон 599 за период с 1983 по 2025 год и обнаружил в этих данных скрытый ритм, указывающий на работу двух взаимосвязанных механизмов.
Ученые РГУ нефти и газа (НИУ) имени И. М. Губкина разработали синтетическое масло для газопоршневых двигателей, позволяющее снизить расход топливного метана на семь процентов. Продукт разработан в целях импортозамещения в сфере энергетики. Разработка открывает новые возможности распределенной энергетики на Крайнем Севере, Дальнем Востоке и других территориях без центральных сетей.
Кит живет двести лет, умеет пробивать головой полуметровый лед и поет океанский джаз голосом несмазанной дверной петли. Охотоморские гренландские киты — это не просто многотонные ледоколы. Это древние узники, которые остались жить в Охотском море со времен последнего оледенения. Это счастливцы, которые смогли пережить гарпуны китобоев XIX-XX веков, но сегодня уязвимы не меньше. Чтобы спасти этих поразительных китов, российским ученым и команде фонда «Природа и люди» приходится: считать хвосты, читать биографии по шрамам, прятать подростков от хищников, стрелять (спутниковыми метками) с парамоторов и тяжелых дронов. Рассказываем, как устроена жизнь гренландских китов России и кто помогает им не исчезнуть навсегда с лица планеты.
Процессы, сопровождающие жизнь черных дыр, интересуют не только теоретиков. Ученые уже знают, что энергия и частицы могут покидать черные дыры и теперь работают над способами эту энергию использовать.
Вселенная может оказаться «замкнутой» глобальной структурой, где свет от далеких галактик способен возвращаться к наблюдателю с разных направлений. Именно такой сценарий не удалось исключить авторам нового масштабного обзора. Проверить его предсказания астрономы смогут уже в ближайшие годы.
Ученые впервые на молекулярном уровне доказали, что обычная вода одновременно состоит из двух разных жидких состояний — более плотного и менее плотного, которые непрерывно сменяют друг друга. Раз молекулярная «двойственность» действительно существует, это подтверждает спорную 30-летнюю гипотезу. Новое открытие поможет, наконец, объяснить десятки «странных» физических аномалий воды, включая ее расширение при замерзании и парадоксальное изменение вязкости под давлением.
Видеосервисы стали неотъемлемой частью жизни россиян. В 2026 году охваты большинства платформ продолжают расти, в том числе YouTube.

Вы попытались написать запрещенную фразу или вас забанили за частые нарушения.
Понятно
Что-то в вашем комментарии показалось подозрительным, поэтому перед публикацией он пройдет модерацию.
Понятно
Из-за нарушений правил сайта на ваш аккаунт были наложены ограничения. Если это ошибка, напишите нам.
Понятно
Наши фильтры обнаружили в ваших действиях признаки накрутки. Отдохните немного и вернитесь к нам позже.
Понятно







Мы скоро изучим заявку и свяжемся с Вами по указанной почте в случае положительного исхода. Спасибо за интерес к проекту.
Понятно