Пародийный чат-бот из 1960-х годов превзошел GPT-3.5 в тесте Тьюринга
Чат-бот «Элиза», написанный в 1966 году, в разговоре с людьми смог лучше убедить их в том, что является человеком, чем чат-бот GPT-3.5, который создали в 2022-м. Авторы нового исследования отметили, что тест Тьюринга, который многие специалисты считают золотым стандартом оценки способностей искусственного интеллекта, может быть неточным.

Британский математик и криптограф Алан Тьюринг некогда задался вопросом, может ли машина мыслить и вести себя в разговоре с людьми как человек. Рассуждения на эту тему привели его в 1950 году к созданию известного теста. Сегодня его используют для того, чтобы определить умение чат-ботов притворяться человеком.
Выглядит этот тест следующим образом. Пользователь через специальную программу общается с одним компьютером и одним человеком. При этом он не знает, кто есть кто. На основании ответов на вопросы необходимо определить, с кем разговаривает испытуемый: с человеком или чат-ботом. Задача машины — ввести в заблуждение, заставить сделать неправильный выбор.
Если на протяжении определенного времени «подопытный» не может отличить программу от человека, считается, что машина успешно завершила тест. Однако многие специалисты называют этот тест субъективным, ведь до сих пор нет единого мнения о том, что необходимо считать показателем успешной его сдачи.
Еще больше неурядиц в этот вопрос внесли исследователи из Калифорнийского университета в Сан-Диего (США). Они создали специальный сайт, с помощью которого провели онлайн-тест Тьюринга. Задачей было узнать, какой из «собеседников» лучше других выдаст себя за человека: модели искусственного интеллекта GPT-4, GPT-3.5, «Элиза» (ELIZA) или группа людей. Результаты работы опубликованы на сайте электронного архива препринтов arXiv.
Всего в эксперименте участвовали 652 человека. Через сайт во время более чем тысячи сессий они взаимодействовали с тремя моделями искусственного интеллекта (GPT-4, GPT-3.5, «Элиза») или другими людьми. После чего испытуемые должны были сообщить, с кем общались: человеком или чат-ботом.
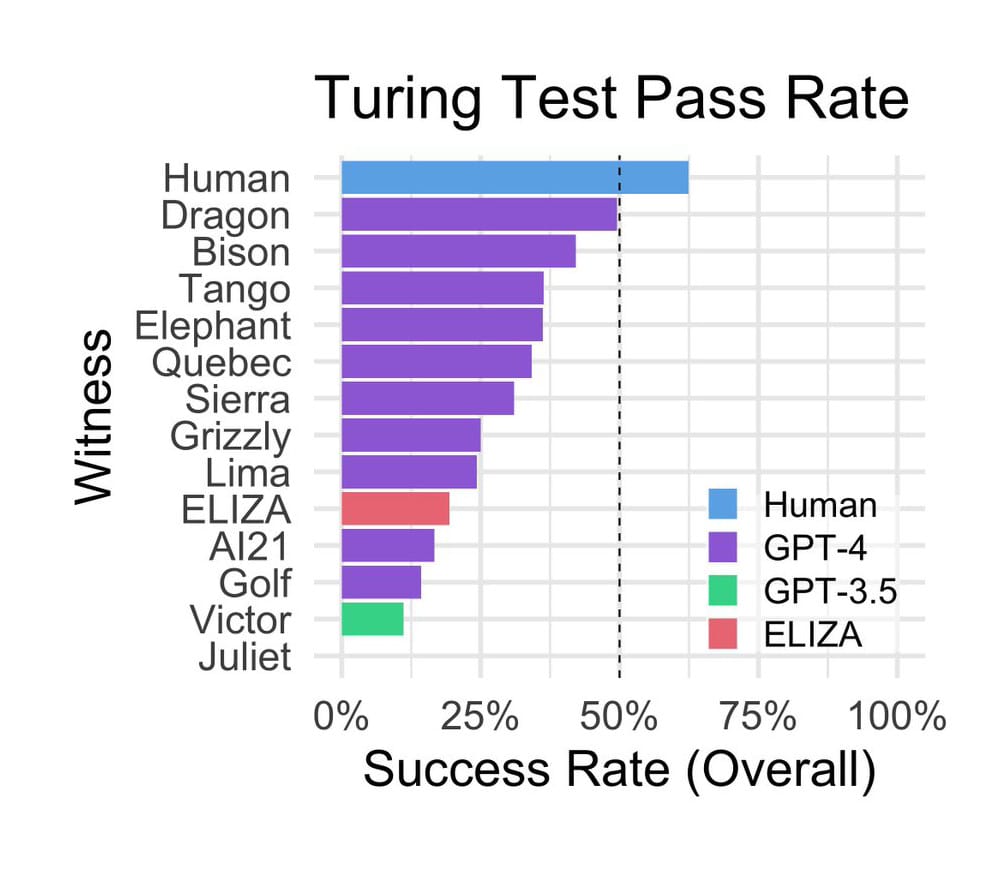
Исследование показало, что людей «по ту сторону экрана» участники эксперимента правильно определили в 63 процентах случаев, а в 37 процентах посчитали их ботами. Модели GPT-4 и GPT-3.5 убеждали испытуемых, что те общаются с человеком в 41 и 14 процентах случаев соответственно. Больше всего ученых удивил «старичок» — чат-бот «Элиза», созданный в 1966 году американским ученым Джозефом Вейценбаумом (Joseph Weizenbaum) для пародирования общения психоаналитика с клиентами. Показатель успешности этой языковой модели составил 27 процентов, то есть гораздо выше, чем у «молодой» GPT-3.5, чего никак не рассчитывали увидеть ученые.
Успех «Элизы» авторы статьи объяснили тремя причинами:
1. Ответы этого чат-бота, как правило, были консервативны, что создавало впечатления «несговорчивого собеседника». Такое «поведение» позволило не разоблачить систему. «Элиза» сводила к минимуму выдачу неверной информации;
2. «Элиза» не показывала тех качеств, с которыми пользователи привыкли ассоциировать современные языковые модели, такие как услужливость, дружелюбие и многословие;
3. «Испытуемые» сообщили, что чат-бот «слишком плох, чтобы походить на модель искусственного интеллекта», поэтому, скорее всего, с ним общался человек.
Во время сеансов участники эксперимента вели светские беседы с «собеседниками», интересовались их знаниями и мнениями об актуальных событиях. Кроме того, общались на иностранном языке и довольно часто обвиняли в том, что они модель искусственного интеллекта, то есть «давили на психику».
Испытуемые принимали решения о том, общался с ними человек или чат-бот, в первую очередь на основе манеры общения и эмоциональных черт «собеседника», а не только на восприятии их уровня интеллекта. Также пользователи отмечали, когда ответы на их вопросы были слишком формальными или неформальными, когда ответам не хватало индивидуальности или они казались обобщенными.
Авторы признали некоторые недостатки своего исследования. В частности, слишком малую выборку и отсутствие стимулов для участников, что, возможно, повлияло на их ответы — вероятно, они не были искренними.
Также ученые отметили, что результаты их работы в какой-то степени показали несостоятельность теста Тьюринга, особенно если брать в расчет производительность «Элизы». То есть этот тест может быть неточным в оценке способностей искусственного интеллекта. Модель «Элиза» гипотетически должна была справиться хуже с заданием, чем GPT-3.5. Исследователи подчеркнули: их выводы не означают, что от теста нужно срочно отказываться. Он по-прежнему актуален и вполне жизнеспособен.
Что касается GPT-3.5 — это базовая модель, бесплатная версия ChatGPT. Команда OpenAI специально разрабатывала ее для того, чтобы та не выдавала себя за человека. Это может хотя бы частично объяснить ее низкую результативность в эксперименте.

 Telegram
Telegram  Дзен
Дзен Правильно подобранные звуковые последовательности способны не только стимулировать рост растений, но и влиять на их урожайность. К такому выводу пришли авторы нового исследования. Они разработали технологию, которая позволяет воздействовать на процессы развития растений через акустические сигналы без использования генной инженерии или химикатов. В экспериментах добились повышения урожайности мяты, сои, болгарского перца и конопли.
Формально почти вся программа тринадцатого полета самой большой ракеты в истории выполнена. Однако испытания показали неполную отлаженность ключевого элемента системы. SpaceX оказывается в ситуации действительно плотных сроков: до намеченного возвращения людей на Луну всего два года и два месяца.
Сегодня на земле существует примерно 7500 языков, однако ученые давно подозревали, что в прошлом их было значительно больше. Международная группа лингвистов реконструировала историю языкового разнообразия за последние 12 тысяч лет и пришла к выводу, что человечество уже пережило «золотой век» языков, после которого их число начало быстро сокращаться.
Правильно подобранные звуковые последовательности способны не только стимулировать рост растений, но и влиять на их урожайность. К такому выводу пришли авторы нового исследования. Они разработали технологию, которая позволяет воздействовать на процессы развития растений через акустические сигналы без использования генной инженерии или химикатов. В экспериментах добились повышения урожайности мяты, сои, болгарского перца и конопли.
Формально почти вся программа тринадцатого полета самой большой ракеты в истории выполнена. Однако испытания показали неполную отлаженность ключевого элемента системы. SpaceX оказывается в ситуации действительно плотных сроков: до намеченного возвращения людей на Луну всего два года и два месяца.
Ученые КНИТУ-КАИ предложили усовершенствованную пресс-форму для компрессионной консолидации в вакууме композиционных материалов и пластмасс с герметичной внутренней полостью. Изобретение относится к области обработки материалов давлением при воздействии вакуума, в частности к устройствам с герметичной внутренней полостью для компрессионной консолидации термопластичных композиционных материалов.
Видеосервисы стали неотъемлемой частью жизни россиян. В 2026 году охваты большинства платформ продолжают расти, в том числе YouTube.
Древнеримские инженеры проложили колоссальную сеть дорог через Европу, Северную Африку и Ближний Восток, многие участки которой до сих пор поражают безупречной прямолинейностью. Секрет строительства заключался в использовании трех особых геодезических инструментов, с помощью которых разбивали местность на ровные отрезки и размечали трассы.
Очереди на заправках стали привычным явлением в России, а на фоне информационного вакуума от властей о конкретных показателях производства бензина в июне население вынуждено ориентироваться на слухи. Все это выглядит довольно странно, но есть нюанс: скорее всего, кризис уже начинает выдыхаться. Как именно мы это выяснили?

Вы попытались написать запрещенную фразу или вас забанили за частые нарушения.
Понятно
Что-то в вашем комментарии показалось подозрительным, поэтому перед публикацией он пройдет модерацию.
Понятно
Из-за нарушений правил сайта на ваш аккаунт были наложены ограничения. Если это ошибка, напишите нам.
Понятно
Наши фильтры обнаружили в ваших действиях признаки накрутки. Отдохните немного и вернитесь к нам позже.
Понятно






Мы скоро изучим заявку и свяжемся с Вами по указанной почте в случае положительного исхода. Спасибо за интерес к проекту.
Понятно
Последние комментарии