- 17.06.2022, 11:42
- Денис Тулинов
-
12,1 тыс
Что мы можем извлечь из «черного ящика»?
Данный материал доступен в формате подкаста.
Машинное обучение ассоциируется чаще всего с распознаванием и генерацией изображений. Системы искусственного интеллекта, такие как DALL-E или Imagen, впечатляют созданием картинок, которые все труднее отличать от иллюстраций художников или фотографий. Лица, синтезированные нейронными сетями, становятся все реалистичнее и даже вызывают у людей больше доверия, чем снимки настоящих людей.

На экране монитора генеративные сети уже «оживляют» умерших знаменитостей: например, на выставке, посвященной Сальвадору Дали, посетителей приветствует сам Дали, произносящий вдохновенную речь своим голосом и с присущими ему экспрессией и мимикой. Дипфейк создает полную иллюзию, словно видео с живым художником записано незадолго до события.
В работе с текстом нейросети не отстают от обученных на изображениях. Добротный онлайн-перевод с одного языка на другой уже занимает секунды, но еще дальше продвинулись большие языковые модели. Они читают текст и могут ответить на вопросы о прочитанном, исходя из логики и здравого смысла. Даже юмор им становится доступен. При этом количество параметров таких сетей неуклонно растет.
Недавно представленная система PaLM вмещает 540 миллиардов параметров, что в три раза больше знаменитой GPT-3. В Китае, используя экзафлопсный суперкомпьютер, создают систему BaGuaLu для обучения модели с 14,5 триллиона параметров. Как пишут разработчики, BaGuaLu потенциально «имеет возможность обучать модели с 174 триллионами параметров, что превосходит количество синапсов в человеческом мозге».
И хотя прорывы в работе с изображениями и текстами последние годы на виду, успехи машинного обучения этим не исчерпываются. Способность нейронных сетей обучаться и затем анализировать большие объемы данных уже востребована во многих областях. Рассмотрим эти менее хайповые, но не менее важные применения МО чуть подробнее.
Как мы поймем, из чего все сделано (физика)
Вот уже десяток лет алгоритмы машинного обучения играют важную роль в исследованиях на Большом адронном коллайдере. Машинное обучение используют для моделирования и калибровки детекторов, сбора данных, распознавания образов и идентификации частиц. Оно становится привычным инструментом во всех аспектах исследований в области физики: в экспериментах — от их разработки и оптимизации до сбора и анализа данных, в численном моделировании и даже в разработке теории.

Как правило, ученые ищут сверхредкие и тонкие отклонения от Стандартной модели. Часто бывает так, что ни одно не является уникально аномальным — только в контексте многих примеров можно построить статистическое доказательство открытия. Словом, и здесь образуется большой поток сложных данных от экспериментальных установок, и в этом запутанном ландшафте с помощью машинного обучения физики ищут закономерности, тенденции и аномалии, чтобы извлечь из данных значимые выводы.
В теоретической физике математическую концепцию или модель часто используют для создания синтетических данных — набора данных результатов моделирования. Системы Machine Learning, обученные на таких данных, оказались способны делать прогнозы для моделей стабильности планетарных систем, генерировать гипотезы в теории узлов и теории представлений.
Студенты магистерской программы Университета «МИСИС» «Полупроводниковые преобразователи энергии» участвуют в экспериментах, проводимых в рамках коллаборации LHCb (ЦЕРН) для фундаментальных исследований новых частиц легкой темной материи.
Прикладные физики пошли еще дальше — они научили нейронную сеть управлять настоящим термоядерным реактором. Внутри его катушки мощные магнитные поля удерживают раскаленную плазму. Магниты не дают ей коснуться стенок реактора, и задача состоит в том, чтобы удержать плазму внутри реактора достаточно долго для того, чтобы извлечь из нее энергию. Удержание плазмы требует постоянного контроля и управления магнитным полем, и ученые обучили нейронную сеть на симуляции.
Как только она смогла контролировать и изменять форму плазмы внутри виртуального реактора, ее переключили на настоящий экспериментальный токамак в Лозанне. В общей сложности управление реактором длилось всего две секунды, но в физике высоких энергий две секунды — это целая эпоха. Алгоритм 10 тысяч раз в секунду (!) проводил 90 различных измерений, описывающих форму и положение плазмы, и регулировал напряжение в 19 магнитах.
Как мы себе объясним, каким образом это связано между собой (химия)
Многие действующие концепции в химии были разработаны на основе относительно небольших наборов данных и поэтому могут быть весьма предвзятыми. Машинное же обучение дает химикам возможность вернуться к истокам и разработать новые правила на основе действительно крупных наборов данных. Идея состоит в том, чтобы изучить статистическую связь между химической структурой и потенциальной энергией, не полагаясь на привычные представления о химических связях или знаниях о взаимодействиях.
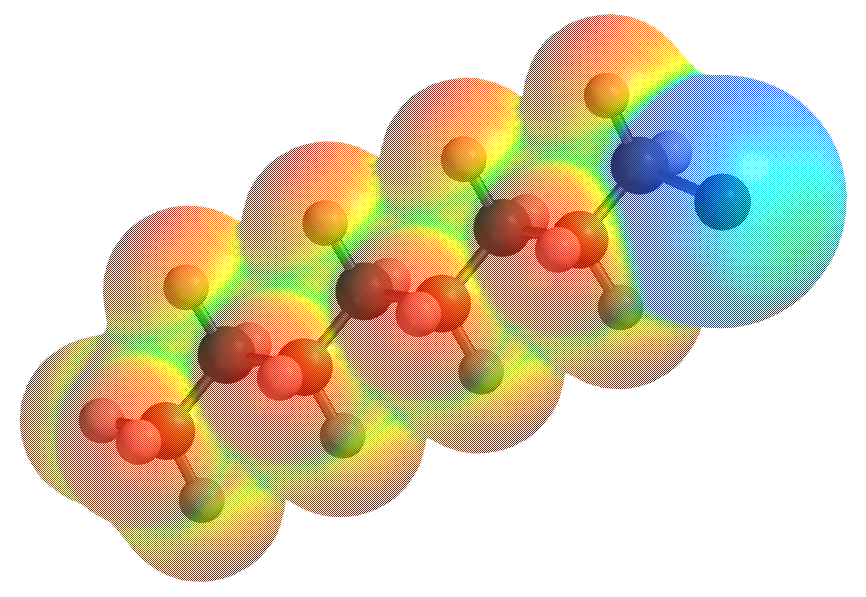
Чтобы рассчитать динамику молекул, необходимо знать силы, действующие на отдельные атомы на каждом временном шаге моделирования. Есть точный способ узнать эти силы: нужно решить уравнение Шрёдингера, которое описывает физические законы, лежащие в основе большинства химических явлений и процессов. Однако аналитическое решение возможно только для относительно простых систем из двух тел, например таких как атом водорода. Для более крупных химических структур уравнения можно решить лишь приблизительно, но даже такое решение потребует очень сложных (и долгих) вычислений.
Машинное же обучение позволяет кардинально сократить время и ресурсы без необходимости решать какие-либо уравнения. Благодаря этой уникальной способности МО в последние годы становится все более популярным среди химиков. Эти методы позволяют исследовать химическое пространство и предсказывать свойства соединений с высокой точностью.
Кроме того, методы МО привели к новым химическим открытиям в системах, которые уже считались хорошо изученными. Стало ясно, что даже относительно небольшие молекулы проявляют нетривиальные электронные эффекты, которые влияют на их динамику и позволяют лучше понять экспериментальные наблюдения. Благодаря МО многие другие неизвестные химические эффекты еще ждут своего открытия — и уже вскоре дождутся.
Из чего мы все построим (дизайн материалов)
Устойчивое развитие и грядущий уже вскоре экономический уклад настойчиво требуют поиска новых материалов с новыми и заранее хорошо прогнозируемыми свойствами. Все «низковисящие плоды» в материаловедении уже собраны, традиционные методы уже не справляются с растущей структурной сложностью материалов, которые нам нужны. Проблема их проектирования в том, что пространство потенциальных реализаций огромно: зачастую оно не поддается вычислениям напрямую, а физическая интуиция оказывается бессильной.
Алгоритмы машинного обучения становятся важным инструментом в проектировании материалов благодаря своей способности предсказывать свойства, генерировать структуры с нуля и открывать новые механизмы далеко за пределами человеческой интуиции. С помощью МО можно искать скрытые законы и зависимости в накопленных данных, предсказывать свойства новых, еще не существующих материалов, а затем оптимизировать их.
Например, различные композиты, полимеры, катализаторы, а также так называемые энергетические материалы, такие как батареи, электролиты, электроды, фотогальваника, уже сейчас успешно проектируются с помощью машинного обучения.
В Университете «МИСИС» готовят специалистов в области искусственного интеллекта, data science, big data, робототехники. Среди партнеров магистерских программ — Сбер, один из российских лидеров в области ИТ, который предоставляет студентам свою инфраструктуру для исследований.
Машинное обучение успешно применяют в синтезе полупроводниковых, металлических, углеродных и полимерных наночастиц. Такие частицы используются буквально повсюду: в химическом зондировании, медицинской диагностике, катализе, термоэлектрике, фотовольтаике или фармацевтике. Их синтезируют с точно контролируемыми свойствами, и машинное обучение помогает искать оптимальные сочетания параметров.
Напомним, что синтетические полимеры имеют поистине бесчисленные комбинации мономеров, которые могут вести к различным сочетаниям структуры-функции (например, ионная проводимость, эффективность фотопреобразования, реакция памяти формы и самовосстановление). Для дизайнера материалов это настоящее проклятие размерности — настолько высокую комбинаторную сложность нельзя вычислить или вывести из общих принципов. Машинное обучение с его способностью выявлять скрытые взаимосвязи и корреляции, и ориентироваться в сложных структурно-функциональных ландшафтах помогает справиться с этим проклятием — генерируя структуры на основе заданных функций подобно тому, как нейронные сети генерируют изображения из текста.
Каким образом мы построим все, что нам нужно (инженерия)
По тем же причинам, что рассмотрены в предыдущей главе, машинное обучение может быть полезно и в разработке сложных устройств, где есть огромный объем параметров и данных. Например, Боинг 787 состоит из 2,3 миллиона деталей, а во время летных испытаний он получает данные от 200 тысяч мультимодальных датчиков. В процессе эксплуатации самолет генерирует множество данных, которые собираются и обрабатываются с помощью 18 миллионов строк кода, и это только для систем авионики и управления полетом!

Проектирование самолета — это многокритериальная оптимизационная задача с ограничениями, которыми служат требования на уровне конструкции, такие как дальность полета или запас топлива, а также производственные и коммерческие ограничения, такие как стоимость или будущий доход. Данные можно использовать для изучения взаимодействий разных параметров, обеспечивая основу для успешного реинжиниринга. Машинное обучение здесь сочетается с технологией цифрового двойника, что позволяет прогнозировать и оптимизировать работу реальных устройств.
Помимо огромных объемов данных, которые обычными способами уже почти невозможно обработать, инженеры могут столкнуться с другой проблемой, где использование машинного обучения прямо напрашивается — если устройство имеет высокую степень свободы. Например, моделирование «мягких» роботов затруднено тем, что податливость и вязкоупругость материала приводит к сложному и непредсказуемому поведению из-за нелинейности, то есть связь между входом и выходом робота не может быть представлена простой линейной зависимостью. Машинное обучение особенно эффективно именно в нелинейных задачах, и его используют в «мягкой» робототехнике: для калибровки мягких датчиков, позиционирования приводов, захвата и планирования движения роботов.
В 2021 году команда студентов Университета «МИСИС» разработала прогностическую модель для газораспределительной сети Москвы, которая может по положениям клапанов предсказывать параметры давления и потребления газа как промышленными предприятиями, так и частными пользователями. Это поможет в управлении сложной газовой системой столицы: сделает ее более энергоэффективной и безопасной.
Машинное обучение также применяют для настройки квантовых устройств, то есть для поиска набора параметров, которые кодируют и оптимизируют кубит. Например, компания DeepMind преодолела барьер сложности на полупроводниковых устройствах с квантовыми точками с помощью методов машинного обучения. Для настройки квантовых устройств в режиме реального времени МО применяют и в других реализациях кубитов: таких как сверхпроводящие кубиты, или центры азотных вакансий в алмазе, или ионные ловушки.
А теперь поговорим за жизнь (биология)
Похожая ситуация сложилась в биологии, где ученые также сталкиваются с огромным и многомерным пространством потенциальных структур, в первую очередь таких важных биологических молекул, как ДНК, РНК и белки. И точно так же трудно выяснить, как именно будет складываться молекула белка, если известен только состав и порядок входящих в нее аминокислот. Трехмерная структура белка определяет его свойства, поэтому этот вопрос всегда был актуальным для биологов. Машинное обучение помогло решить эту проблему.
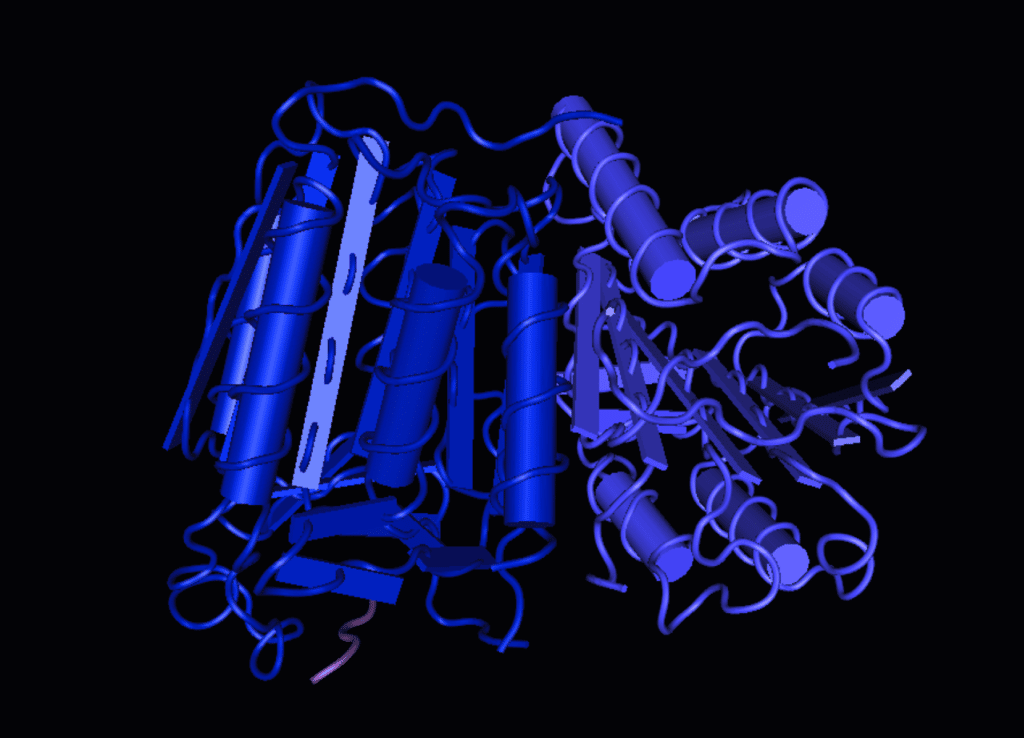
В 2015 году AlphaGo, программа DeepMind, обыграла сначала «белкового» чемпиона Европы по игре в го, а затем и чемпиона мира. Программа использовала глубокие нейронные сети и обучалась сначала на основе сыгранных людьми партий, но следующая версия программы играла уже сама с собой и самостоятельно наращивала свой уровень, уже без подсказок из игр между людьми.
Го потенциально содержит огромное пространство комбинаций, что роднит эту игру с проблемой сворачивания белка (фолдинга). Создатели AlphaGo решили проверить возможности своей программы в биологической области, обучив AlphaFold на базах данных об уже известных белковых структурах. Задача AlphaFold состояла в том, чтобы предсказать наиболее вероятные структуры белков, о которых ей известно лишь то, что они сворачиваются.
Программа продемонстрировала высокую точность в прогнозировании укладки белков, и для этого ей не требовалось вычислять кинетику или стабильность фолдинга. AlphaFold набрала 90 баллов из 100 в ежегодном конкурсе «Крупномасштабный эксперимент по предсказанию структуры белка» (CASP), после чего многие специалисты сочли проблему предсказания структуры белка в целом решенной.
AlphaFold продемонстрировала возможности машинного обучения в вопросе, который трудно решить другими методами. Центральным компонентом AlphaFold является нейронная сеть, которая обучена на очень большом количестве структур для предсказания расстояний между атомами. AlphaFold может стать полезной технологией, например для проектирования лекарств, где отправной точкой часто является знание структуры белка.
Как мы всех вылечим от всего. Ну почти! (медицина)
Путь от открытия лекарства до его выхода на рынок обходится в среднем более чем в 1 миллиард долларов США и может занять 12 лет и более. Много усилий уходит на поиск и разработку действующего вещества, и не меньше усилий требуется для того, чтобы убедиться, что препарат действительно работает на людях. Все дело в чрезвычайной сложности организма и взаимосвязей клеток, биомолекул, генов и других веществ. Эта сложность, как уже сказано, не поддается прямому анализу. Зато порой, как выяснилось, она поддается машинному обучению.

При этом в медицине наблюдается бурный рост доступности клинических данных, отражающих информацию на разных уровнях биологической сложности, таких как мультиомика, молекулярные пути, данные визуализации, электронные медицинские карты, а также данные с имплантируемых устройств и носимых датчиков. И все эти данные можно «скормить» машинному обучению, получив интересные результаты.
Машинное обучение уже широко используют в полногеномных ассоциативных исследованиях (GWAS), где информация о геноме увязана с признаками здоровья. Следующий шаг — дополнить анализ данными эпигенетики, протеомики, метаболомики и так далее. Это требует больших ресурсов, но отдача может быть высокой, поскольку машинное обучение способно справиться с разнородными и сложными данными, находя в них скрытые от человеческого взгляда взаимосвязи. Например, с помощью МО уже показано, что ответы на антидепрессанты или на лечение рака можно предсказать на основе геномики и клинических данных, что поможет пациентам избежать ненужных процедур, часто при этом сложных и дорогих.
В 2020 году коллаборация ученых Университета «МИСИС», Института русского языка им. В. В. Виноградова РАН и НИУ ВШЭ запустила масштабный проект по созданию с помощью технологий искусственного интеллекта и машинного обучения уникальной базы древнеславянских рукописных текстов — корпуса. Это даст исследователям-лингвистам и историкам мощный инструмент для изучения всех современных национальных славянских языков и культур и станет уникальным ключом к пониманию их наследия.
Методы машинного обучения все чаще применяют для скрининга лекарств, прогнозирования их свойств и поиска терапевтических мишеней. И есть определенная надежда, что МО поможет пролить свет на природу и развитие сложных заболеваний, таких как рак или болезнь Альцгеймера. Например, анализ более 11 тысяч опухолей 33 типов рака существенно улучшил понимание того, как рак мутирует из исходных клеток и какие факторы влияют на развитие опухоли. Глубокое понимание рака жизненно необходимо: многие лекарства разрабатывают на основе экспериментально подтвержденной гипотезы, которая может объяснить возможный механизм канцерогенеза, но игнорирует другие факты о болезни.
Машинное обучение в медицине поможет врачам принимать решения и улучшит диагностику и прогнозирование за счет выявления новых закономерностей. Проблема же заключается в том, как обеспечить интерпретируемость моделей глубокого обучения, так что тут предстоит еще большая работа.
Что у нас может не получиться?
Нейронная сеть получает данные на вход и выдает результат на выходе. Невозможно судить, верно ли она отражает реальность, если правильный ответ не известен заранее. Сам процесс «рассуждений» нейросети скрыт от нашего наблюдения (и даже само слово «рассуждения» мы должны поэтому забирать в кавычки) — недаром мы называем его «черным ящиком» — и для чувствительных областей вроде медицины или сферы безопасности это серьезная проблема, которую еще предстоит решить. Там необходима твердая уверенность, что нейросеть не пошла по ложному следу, что она уловила реальную закономерность, а не артефакт.
Другой проблемой может быть приблизительный характер ответов в машинном обучении. Там, где неидеальные ответы допустимы, а ставки невелики, например при создании изображений или языковом переводе, методы машинного обучения демонстрируют свою мощь, и мы им можем сразу доверять. В диагностике или управлении автомобилем пойти на такой риск нельзя, поэтому глубокие нейронные сети все еще не произвели революцию в этих областях.
Кроме того, нейронные сети сильно зависят от качества данных, на которых они обучаются. Мусор на входе закономерно даст мусор на выходе, а чистые, качественные данные для обучения собрать в реальном мире трудно или же очень затратно. Кроме того, даже чистые данные могут сформировать у нейросети предвзятость, поскольку разные предубеждения и искажения могут присутствовать в обучающей выборке, пусть неявно.
Нет сомнений, что обученные нейросети эффективны в различении паттернов и поиске связей, но эти связи ассоциативны, они не обязаны указывать на причины и следствия. В некоторых случаях, особенно в науке, где поиск причин (а не корреляций) может быть целью, такое свойство машинного обучения будет считаться недостатком.
Не стоит забывать и о том, что глубокое обучение прожорливо. Хороший результат требует огромных объемов данных для обучения, а большие модели (например, языковые) требуют мощных вычислительных ресурсов и в конечном счете затрат энергии (и ресурсов). Это во многом ограничивает применение МО в различных отраслях.
Наконец, сети глубокого обучения способны ошибаться, причем иногда вопиюще глупо, вплоть до смешного. Это признак того, что на самом деле они не обладают пониманием, и уж тем более не мыслят и не познают мир, а всего лишь реагируют на паттерны в статистике. Это очень полезное умение, оно позволяет решать задачи определенного класса, но не стоит ждать от нейросетей того, что они дать не в состоянии. При грамотном применении у машинного обучения мощный потенциал, но будущим поколениям специалистов еще только предстоит его полностью раскрыть.
Если вам было интересно читать этот текст и вы хотите попробовать себя в этой области, рекомендуем магистратуру «Искусственный интеллект и машинное обучение» в Университете «МИСИС».
 Telegram
Telegram  Дзен
Дзен Исследователи из США нашли в организме человека ранее неизвестный пептид BRP и проверили его работу на животных. В экспериментах он помог снизить аппетит и процент содержания жира без побочных эффектов. По механизму действия BRP напоминает препараты для снижения веса на основе ГПП-1, к которым относится семаглутид, но, предположительно, действует иначе: не через кишечник и поджелудочную железу, а преимущественно через центральные сигнальные пути в мозге, включая области гипоталамуса, участвующие в регуляции аппетита. Авторы новой научной работы рассматривают открытие как основу для принципиально нового класса лекарств от ожирения.
Четыре точки Европы показали одну и ту же картину: как минимум несколько десятков тысяч лет регулярных сильных пожаров. До сих пор ученые не сталкивались с ископаемыми следами настолько длительных регулярных событий такого типа. Авторы новой работы предложили феномену объяснение, но оно имеет существенные недостатки.
Фестиваль «ИТ КоР» в 2026 году пройдет в пятый раз. «Росатом» проведет мероприятие в Нижнем Новгороде с 28 по 30 октября. Студенты и молодые ИТ-специалисты встретятся с представителями технологических компаний и познакомятся с новыми технологиями.
Правильно подобранные звуковые последовательности способны не только стимулировать рост растений, но и влиять на их урожайность. К такому выводу пришли авторы нового исследования. Они разработали технологию, которая позволяет воздействовать на процессы развития растений через акустические сигналы без использования генной инженерии или химикатов. В экспериментах добились повышения урожайности мяты, сои, болгарского перца и конопли.
Формально почти вся программа тринадцатого полета самой большой ракеты в истории выполнена. Однако испытания показали неполную отлаженность ключевого элемента системы. SpaceX оказывается в ситуации действительно плотных сроков: до намеченного возвращения людей на Луну всего два года и два месяца.
Сегодня на земле существует примерно 7500 языков, однако ученые давно подозревали, что в прошлом их было значительно больше. Международная группа лингвистов реконструировала историю языкового разнообразия за последние 12 тысяч лет и пришла к выводу, что человечество уже пережило «золотой век» языков, после которого их число начало быстро сокращаться.
Видеосервисы стали неотъемлемой частью жизни россиян. В 2026 году охваты большинства платформ продолжают расти, в том числе YouTube.
Древнеримские инженеры проложили колоссальную сеть дорог через Европу, Северную Африку и Ближний Восток, многие участки которой до сих пор поражают безупречной прямолинейностью. Секрет строительства заключался в использовании трех особых геодезических инструментов, с помощью которых разбивали местность на ровные отрезки и размечали трассы.
Очереди на заправках стали привычным явлением в России, а на фоне информационного вакуума от властей о конкретных показателях производства бензина в июне население вынуждено ориентироваться на слухи. Все это выглядит довольно странно, но есть нюанс: скорее всего, кризис уже начинает выдыхаться. Как именно мы это выяснили?

Вы попытались написать запрещенную фразу или вас забанили за частые нарушения.
Понятно
Что-то в вашем комментарии показалось подозрительным, поэтому перед публикацией он пройдет модерацию.
Понятно
Из-за нарушений правил сайта на ваш аккаунт были наложены ограничения. Если это ошибка, напишите нам.
Понятно
Наши фильтры обнаружили в ваших действиях признаки накрутки. Отдохните немного и вернитесь к нам позже.
Понятно






Мы скоро изучим заявку и свяжемся с Вами по указанной почте в случае положительного исхода. Спасибо за интерес к проекту.
Понятно
Последние комментарии