Ученые помогли нейросети лучше ориентироваться в пространстве
Исследователи из НИУ ВШЭ, НИТУ МИСИС и AIRI нашли способ эффективнее проводить обучение с подкреплением для нейросетей, заточенных на ориентацию в пространстве. С помощью механизма внимания эффективность работы графовой нейросети увеличилась на 15 процентов.

Результаты исследования опубликованы в журнале IEEE Access. Человечеству пригодились бы роботы, которые могут сами перенести коробку из точки A в точку B, грузовики, умеющие ездить самостоятельно, и дроны-доставщики, способные не врезаться в деревья. Для ориентации в трехмерном пространстве таким устройствам-агентам обязательно нужны нейросети: окружающая среда требует быстрой реакции и возможности реагировать на изменяющиеся условия.
«Если мы хотим научить агента работать самостоятельно, то должны оценивать его работу в процессе обучения. Нельзя просто дать ему проблему и наблюдать — практически всегда она будет решена не тем образом и не с тем результатом, которого мы хотим. Поэтому нейросеть получает бонусный квест: при выполнении задачи набрать как можно больше очков. Очки даются за продвижение к оптимальному решению. Это и есть обучение с подкреплением. Пока нейросеть обучается, выполняя одно и то же задание много раз, мы оцениваем ее результаты и либо поощряем “наградой” за движение в нужном направлении, либо признаем результат вредным и уменьшаем количество заработанных “очков”», — объясняет один из авторов статьи, аспирант факультета компьютерных наук НИУ ВШЭ Матвей Герасёв.

Ориентирование в пространстве — одна из самых сложных задач в мире нейросетей. Проблема в том, что в этой задаче у нейросети зачастую нет полной информации о ее текущем окружении, например глубины или карты местности. Еще меньше нейросеть знает о перспективах награды: вознаграждение выдается не поэтапно, а один раз в конце, после полного выполнения задания.
Представьте, что вам нужно пройти через лес к башне, заинтересовав как можно больше белок. Важно, что они сидят в основном на самом коротком пути (на пути оптимального решения) и, если увидят вас, пойдут за вами. При этом вы их не видите, где башня — не знаете и количество заинтересовавшихся вами зверей узнаете, только достигнув цели. Такого типа задачи достаются пространственным нейросетям.
Получение награды выражено математически функцией вознаграждения, и нейросеть должна определить ее как можно точнее, чтобы получить большую награду. Хорошая функция помогает сети эффективнее решать задачу и обучаться.
Авторы исследования предложили новый метод формирования функции вознаграждения с учетом специфики однократного получения вознаграждения после полного решения проблемы. Он основывается на дополнительных вторичных вознаграждениях — шейпинге вознаграждения. Ученые применили два способа улучшения техники, которую в 2020 году предложили канадские ученые из Макгиллского университета.
Первый использует продвинутые агрегирующие функции, а второй — механизм внимания. Продвинутые агрегирующие функции учитывают, в каком порядке и что видит нейросеть. В статье ученые указывают на важность подбора агрегирующей функции под архитектуру конкретной нейросети. Механизм внимания позволяет модели сосредоточиться на наиболее важных входных данных при создании прогнозов. Признаки важного, выгодного решения нейросеть находит при сопоставлении последовательных шагов решения задачи.
Исследователи провели серию экспериментов с поэтапным вознаграждением (разреженным вознаграждением, sparse reward). Для них использовали задачи на ориентацию в виртуальных пространствах «Четыре комнаты» и «Лабиринт».
В «Четырех комнатах» нейросеть должна обнаружить красный ящик, который случайным образом появляется в одной из комнат. Нейросеть может перемещаться только прямо, влево или вправо. Ящик — цель механизма внимания. Нейросеть учится параллельно в 16 таких пространствах, совершая пять миллионов действий.
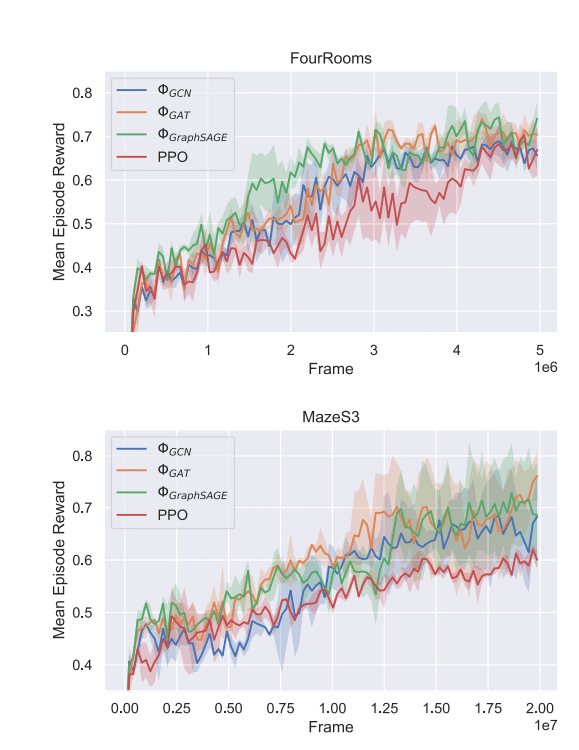
В «Лабиринте» помещенный в произвольную точку агент должен найти выход. Сам лабиринт каждый раз генерируется случайным образом, и для успешного обучения модели требуется пройти 20 миллионов шагов.
Исследование показало, что при формировании функции вознаграждения на основе механизма внимания агент обучается сосредотачиваться на ребрах графа, соответствующих важным переходам в трехмерной среде — тем, при которых цель попадает в поле зрения агента. Это до 15 процентов повышает эффективность работы нейросетей.
«Нам важно было оптимизировать процесс обучения именно для графовых нейронных сетей. Граф нельзя наблюдать целиком напрямую, но для эффективного обучения графовой нейронной сети достаточно рассматривать его части. Их можно наблюдать в виде отдельных траекторий перемещения агента. Таким образом, для обучения необязательны все варианты траекторий. Применение механизма внимания — перспективное решение, поскольку оно существенно ускоряет процесс обучения. Ускорение происходит за счет учета структуры графа марковского процесса, что недоступно неграфовым нейросетям», — рассказывает Илья Макаров, доцент факультета компьютерных наук и приглашенный преподаватель Лаборатории алгоритмов и технологий анализа сетевых структур НИУ ВШЭ в Нижнем Новгороде, руководитель группы «ИИ в промышленности» Института AIRI, директор Центра ИИ МИСИС.
В исследовании использовались ресурсы Программы фундаментальных исследований НИУ ВШЭ и вычислительные ресурсы HPC-кластера НИУ ВШЭ.
 Telegram
Telegram  Дзен
Дзен Виктор Гловер, один из четырех человек, весной этого года пролетевших мимо Луны, выступил на конференции NASA и предложил резко изменить план высадки американцев на Луне в конце десятилетия. Он считает, что это позволит снизить риски для астронавтов-участников миссии.
Исследователи «Яндекса» предложили способ решить проблему «катастрофического забывания» при обновлении слов-триггеров для умных устройств. Гаджеты смогут узнавать новые голосовые команды, продолжая распознавать уже известные. Исследование с описанием подхода авторы представят на международной конференции Interspeech 2026, которая пройдет с 27 сентября по 1 октября в Сиднее.
Как нейросети меняют рынок дизайна, почему брендинг превращается в систему данных и какие навыки будут определять профессию дизайнера в ближайшие годы — рассказывает кандидат технических наук, заведующий кафедрой автоматизированного проектирования и дизайна НИТУ МИСИС Евгений Коржов.
Очереди на заправках стали привычным явлением в России, а на фоне информационного вакуума от властей о конкретных показателях производства бензина в июне население вынуждено ориентироваться на слухи. Все это выглядит довольно странно, но есть нюанс: скорее всего, кризис уже начинает выдыхаться. Как именно мы это выяснили?
В позднеантичном Риме императорским указом мужчинам запретили носить длинные волосы. Автор нового исследования пришел к выводу, что введение этого запрета объяснялось необходимостью сохранения римской идентичности в условиях усиливающегося распада империи и нарастающего торжества варваров.
Виктор Гловер, один из четырех человек, весной этого года пролетевших мимо Луны, выступил на конференции NASA и предложил резко изменить план высадки американцев на Луне в конце десятилетия. Он считает, что это позволит снизить риски для астронавтов-участников миссии.
Вселенная может оказаться «замкнутой» глобальной структурой, где свет от далеких галактик способен возвращаться к наблюдателю с разных направлений. Именно такой сценарий не удалось исключить авторам нового масштабного обзора. Проверить его предсказания астрономы смогут уже в ближайшие годы.
Ученые впервые на молекулярном уровне доказали, что обычная вода одновременно состоит из двух разных жидких состояний — более плотного и менее плотного, которые непрерывно сменяют друг друга. Раз молекулярная «двойственность» действительно существует, это подтверждает спорную 30-летнюю гипотезу. Новое открытие поможет, наконец, объяснить десятки «странных» физических аномалий воды, включая ее расширение при замерзании и парадоксальное изменение вязкости под давлением.
Видеосервисы стали неотъемлемой частью жизни россиян. В 2026 году охваты большинства платформ продолжают расти, в том числе YouTube.

Вы попытались написать запрещенную фразу или вас забанили за частые нарушения.
Понятно
Что-то в вашем комментарии показалось подозрительным, поэтому перед публикацией он пройдет модерацию.
Понятно
Из-за нарушений правил сайта на ваш аккаунт были наложены ограничения. Если это ошибка, напишите нам.
Понятно
Наши фильтры обнаружили в ваших действиях признаки накрутки. Отдохните немного и вернитесь к нам позже.
Понятно







Мы скоро изучим заявку и свяжемся с Вами по указанной почте в случае положительного исхода. Спасибо за интерес к проекту.
Понятно