


Сегодня алгоритмы машинного обучения управляют колоссальными потоками информации: они рекомендуют товары, одобряют кредиты, формируют новостные ленты и даже помогают полиции предсказывать районы совершения преступлений. Однако широкое внедрение таких систем породило неочевидную проблему: алгоритмы начинают менять ту самую среду, которую они призваны анализировать. Когда банк отказывает в кредите на основе прогноза модели, это решение меняет статистику выдачи займов. Когда рекомендательная система предлагает пользователю определенный контент, она формирует его будущие предпочтения.
В результате новые данные, на которых система будет переобучаться, становятся искаженным отражением ее прошлых предсказаний. Возникает скрытая петля обратной связи, эффект которой до сих пор описывался в основном эмпирически, но не имел строгого математического обоснования.
В классической теории статистики и машинного обучения принято считать, что данные приходят из внешнего, независимого источника, подобно тому как астроном наблюдает за звездами, не в силах повлиять на их траекторию. Однако в случае с социальными алгоритмами ситуация напоминает скорее человека, который пытается выучить иностранный язык, читая только свои собственные, написанные с ошибками конспекты. Это нарушение фундаментального принципа независимости данных приводит к дрейфу концепций — явлению, когда связь между входными данными и целевым результатом меняется со временем не из-за внешних причин, а под влиянием самого «наблюдателя» — нейросети.
Команда российских математиков подошла к этой проблеме с инструментарием теории динамических систем. Вместо того чтобы анализировать отдельные ошибки предсказаний, авторы работы рассмотрели эволюцию самих распределений вероятностей данных. Они представили процесс многократного обучения как бесконечную цепочку преобразований, где на каждом шаге функция плотности вероятности данных трансформируется под воздействием так называемого эволюционного оператора. Этот оператор включает в себя весь жизненный цикл модели: от выборки данных и тренировки алгоритма до выдачи прогнозов пользователям и получения обратной связи. Исследование опубликовано в журнале Knowledge and Information Systems, препринт статьи доступен на arXiv.org.
Работа продолжает исследования динамики систем машинного обучения в условиях их взаимодействия с пользователями. В этом случае постановка задачи существенно отличается от классической и требует применения методов исследования, учитывающих их взаимодействие.
В 2021 году было установлено влияние вовлеченности и доверия пользователей на эволюцию системы, и в 2023-м были получены критерии возникновения эффекта положительной обратной связи и возникающего в результате вынужденного смещения данных, но не было строгой математической модели этого эффекта. К построению такой модели с учетом недетерминированности систем машинного обучения и удалось приступить в работе 2024–2025 годов.
Результатом нового исследования стало математическое доказательство того, что у процесса самообучения в замкнутом контуре есть два финальных сценария. Согласно полученным теоремам, распределение ошибок модели с течением времени стремится к одному из двух предельных состояний.
Первый сценарий — коллапс вариативности, когда распределение вырождается в так называемую дельта-функцию Дирака. На практике это означает возникновение жесткой положительной обратной связи: модель становится сверхуверенной в своих узких прогнозах, игнорируя все многообразие реальности.

Второй сценарий, выявленный учеными,— стремление к нулевому распределению, что означает неограниченный рост ошибки и дисперсии. Это состояние соответствует хаотическому развалу системы, когда обратная связь становится отрицательной или деструктивной, и предсказательная способность модели деградирует до уровня хуже случайного угадывания. Исследователи определили математические условия, при которых система сваливается в тот или иной режим, подтвердив гипотезу, выдвинутую Антоном Хританковым в 2021 году, о связи сжимающих отображений с возникновением положительных петель обратной связи.
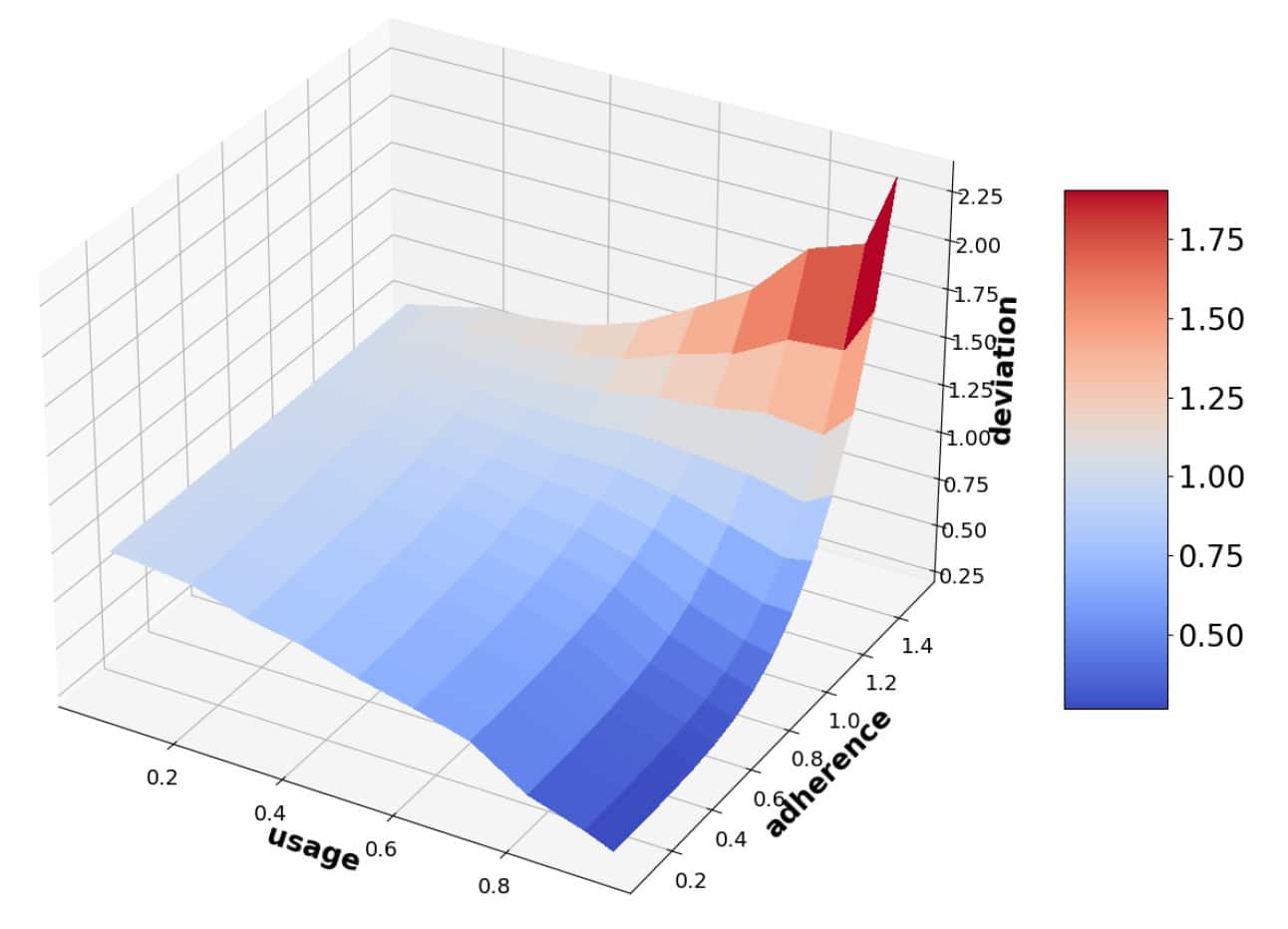
Для проверки своих теоретических выкладок ученые провели серию вычислительных экспериментов на синтетических данных, используя классические задачи линейной регрессии. Они смоделировали две ситуации: «скользящее окно», когда старые данные постепенно забываются, и «выборочное обновление», когда новые предсказания смешиваются с полным набором исторических данных. Результаты симуляций идеально легли на предсказанные теоретические кривые.
Андрей Веприков, магистрант кафедры интеллектуальных систем ФПМИ МФТИ, стипендиат им. К.В. Рудакова, пояснил: «Мы обнаружили, что даже простые модели линейной регрессии при повторном обучении на своих выводах демонстрируют сложное динамическое поведение. В зависимости от параметров — того, насколько пользователи доверяют предсказаниям и как много машинных данных попадает обратно в обучающую выборку,— система неумолимо дрейфует либо к сужению кругозора и «эху», либо к полной потере качества. Наша теория дает инструмент, чтобы заранее увидеть этот тренд, анализируя моменты распределения ошибок, которые гораздо проще измерить на практике».
Антон Хританков, кандидат физико-математических наук, доцент кафедры интеллектуальных систем МФТИ, научный руководитель исследования, подробно рассказал о важности проделанной работы:
«Наша статья — ключевой этап в цикле наших исследований, начатых еще в 2021 году. Если раньше мы фиксировали факты влияния алгоритмов на пользователей и выявляли критерии возникновения «петель обратной связи», то теперь, объединив усилия с коллегами из ИППИ РАН, мы создали полноценный теоретический каркас этого явления.
Общий замысел нашей работы заключается в пересмотре фундаментального подхода к машинному обучению. Традиционная статистика исходит из того, что данные независимы и приходят «извне». Мы же показываем, что современные ИИ-системы — это не пассивные наблюдатели, а активные агенты, которые меняют среду под себя.
Цель построенной нами модели — дать разработчикам понимание того, где проходит граница между стабильной работой алгоритма и его неизбежной деградацией. Мы объяснили природу «цифровых эхо-камер» языком математики. Это позволяет прогнозировать долгосрочные риски внедрения рекомендательных и скоринговых систем, переходя от интуитивной настройки параметров к инженерно обоснованному проектированию устойчивых систем искусственного интеллекта».
Александр Афанасьев, доктор физико-математических наук, заведующий центром распределенных вычислений ИППИ РАН, добавил:
«В этой работе мы поставили перед собой амбициозную задачу: перейти от эмпирических наблюдений за деградацией ИИ к строгому математическому описанию этого процесса. Главным результатом стало построение модели на основе теории динамических систем, где обучение рассматривается как бесконечная цепочка преобразований вероятностных распределений.
Нам удалось строго доказать, что в замкнутом контуре, когда алгоритм учится на собственных данных, поведение системы перестает быть стабильным. Мы математически вывели два финальных сценария «жизни» такой модели. Первый — это коллапс вариативности (стремление распределения ошибок к дельта-функции Дирака), когда нейросеть становится «самоуверенной» и перестает воспринимать реальность. Второй — хаотический развал предсказательной способности.
Важно, что наши теоретические выкладки, предсказывающие поведение моментов распределения ошибок, полностью совпали с результатами численных экспериментов. Это дает нам в руки не просто гипотезу, а работающий инструмент: теперь мы можем анализировать устойчивость алгоритмов еще до их внедрения, просто наблюдая за динамикой статистических моментов».
Результаты исследования могут быть использованы при разработке рекомендательных сервисов, систем скоринга и медицинских диагностических комплексов. Исследователи планируют расширить свою модель, включив в нее метрики расстояния между распределениями, и протестировать теорию на более сложных архитектурах глубокого обучения и реальных датасетах.