



Современные большие языковые модели остаются для своих создателей во многом загадкой. Несмотря на их впечатляющие способности, внутренние механизмы их «мышления» остаются непрозрачными. Это фундаментальная проблема, мешающая созданию по-настоящему надежного и безопасного искусственного интеллекта. Одним из прорывов в этой области стало использование разреженных автоэнкодеров (SAE) — специальных «словарей-дешифраторов», которые позволяют извлекать из сложной активности нейронов отдельные, понятные человеку концепции или «признаки», такие как «научная терминология» или «ссылки на законы физики». Однако ученые не понимали, как проследить «судьбу» одного и того же понятия по мере его продвижения через десятки слоев модели.
Задача, которую поставили перед собой исследователи, — создать «бесшовную» карту, связывающую эти разрозненные этажи и показывающую, как именно информация трансформируется в процессе обработки. Разработанный ими метод позволяет отследить, как конкретные признаки зарождаются, передаются от слоя к слою или исчезают. Для этого ученые использовали не требующий данных подход, основанный на вычислении косинусного сходства между векторами признаков, извлеченных с помощью SAE на разных уровнях модели. Их метод работает как лингвистический компаратор: он берет векторное представление одного понятия на одном слое и ищет в следующем слое наиболее похожее по направлению, тем самым выстраивая цепочку преемственности.
Коллектив ученых смог не просто сопоставить похожие признаки, но и классифицировать их происхождение. Оказалось, что концепции на первых слоях чаще возникают из механизма внимания, отвечающего за понимания контекста, а на более поздних слоях концепции чаще возникают в MLP, в которых хранятся знания модели. Создавая такие «графы потоков» для тысяч признаков, исследователи получили беспрецедентную по своей детализации картину внутренней жизни нейросети. Эта концепция наглядно проиллюстрирована в работе на примере «графа потока» для научных понятий.

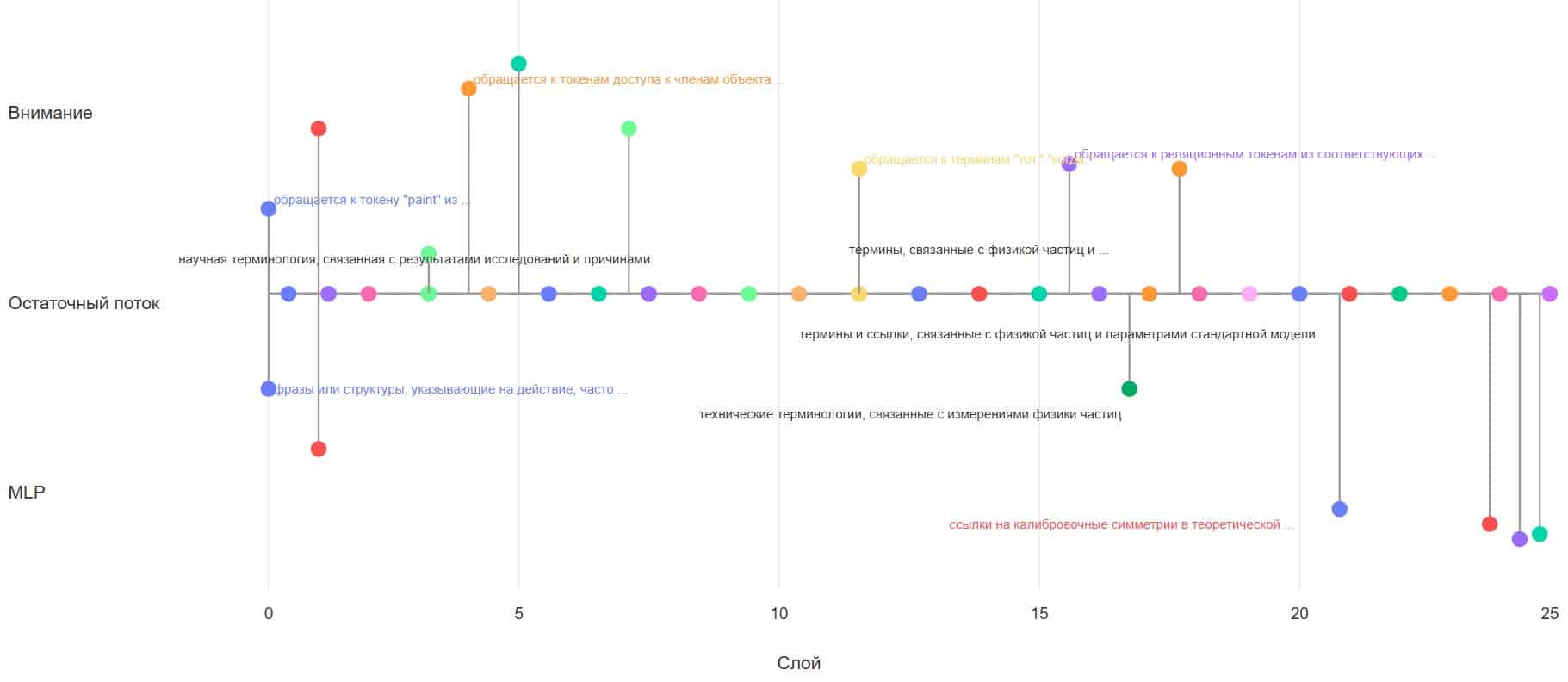
Никита Балаганский, руководитель научной группы LLM Foundations, T-Bank AI Research, аспирант МФТИ, рассказал о сути проведенной работы: «Мы создали своего рода генеалогическое древо для «мыслей» нейронной сети. Наш метод позволяет проследить всю родословную конкретной идеи внутри модели. Мы можем увидеть, как из простых признаков, отвечающих за отдельные слова на ранних слоях, рождаются более сложные семантические конструкции на средних, и как они в итоге собираются в абстрактные темы на финальных этапах. Это похоже на то, как ручейки сливаются в реки, а реки — в океан».
Ключевым результатом исследования стала демонстрация практической пользы созданных карт. Ученые показали, что, зная полную траекторию развития определенной темы, можно гораздо эффективнее управлять генерацией текста. Вместо того чтобы пытаться воздействовать на один признак на одном слое, новый подход позволяет оказывать мягкое, но уверенное воздействие на всю цепочку связанных признаков на разных уровнях. В ходе экспериментов исследователи смогли успешно подавить в генерируемом тексте тему «научных концепций и сущностей», воздействуя на найденный граф потока. Это первая в мире демонстрация такого многоуровневого управления поведением языковой модели.
Уникальность подхода заключается в его простоте и эффективности. Он не требует для анализа огромных массивов данных и сложных вычислений, опираясь лишь на веса уже обученных SAE и самой языковой модели. Это открывает дорогу к его широкому применению для анализа и интерпретации самых разных архитектур нейронных сетей.
Понимание этих потоков — это ключ к созданию более безопасного и предсказуемого искусственного интеллекта. Теперь можно не просто «дергать за одну ниточку» на одном слое, а мягко направлять целый поток связанных «мыслей». Если нужно, чтобы модель избегала определенной темы, то можно ослабить соответствующий ей поток на самых ранних стадиях его зарождения. Это гораздо эффективнее и безопаснее, чем грубое вмешательство на выходе. Практическая значимость этого открытия огромна. Оно предоставляет разработчикам и исследователям мощный инструмент для «отладки» и «тонкой настройки» языковых моделей. С его помощью можно будет выявлять и целенаправленно ослаблять нежелательные концепции, связанные с предвзятостью, токсичностью или дезинформацией, по всей цепочке их формирования. Это также открывает новые возможности для создания моделей с управляемым стилем и тематикой, что крайне востребовано в творческих и образовательных приложениях.
В будущем ученые планируют использовать разработанный метод для анализа самых крупных и современных языковых моделей, а также для исследования более сложных явлений, таких как формирование «внутренних схем рассуждений» в нейросетях. Эта работа делает важный шаг на пути от эмпирического создания искусственного интеллекта к его полноценному проектированию, основанному на глубоком понимании внутренних механизмов.