



В последние годы большие языковые модели совершили настоящий прорыв, научившись вести осмысленный диалог, писать тексты и программный код. Однако у большинства из них долго оставалась «ахиллесова пята» — ограниченный объем «оперативной памяти», или, как говорят специалисты, короткое контекстное окно. Модель могла блестяще оперировать информацией, поданной ей в последних нескольких абзацах, но «забывала» то, что было в начале длинного документа. Это серьезно ограничивало их применение в задачах, требующих анализа больших объемов информации: юридических договоров, научных статей, медицинских карт или целых литературных произведений.
Недавние технологические достижения позволили значительно расширить это окно, и теперь лучшие модели способны «удержать в уме» текст, сопоставимый по объему с романом «Война и мир». Однако вместе с новыми возможностями возник и новый вызов: как объективно измерить, насколько хорошо нейросеть на самом деле «понимает» такой огромный массив данных? Существующие тесты для русского языка были либо слишком простыми, либо не были рассчитаны на такие объемы, а большинство передовых разработок в этой области были созданы для английского языка.
Именно для решения этой задачи команда российских ученых создала LIBRA (Long Input Benchmark for Russian Analysis). Это не просто один тест, а целый комплексный «экзамен», состоящий из 18 заданий различной природы и сложности. Он позволяет оценить, как модель справляется с текстами объемом от четырех тысяч до 128 тысяч токенов (единиц текста, сопоставимых с количеством слов), что эквивалентно диапазону от большой статьи до увесистой книги. Все задания в бенчмарке разделены на четыре группы по возрастанию сложности, что позволяет провести всесторонний анализ способностей нейросети. Работа представлена на международном воркшопе CODI 2025, прошедшем в рамках конференции EMNLP 2025 в Сучжоу (Китай).

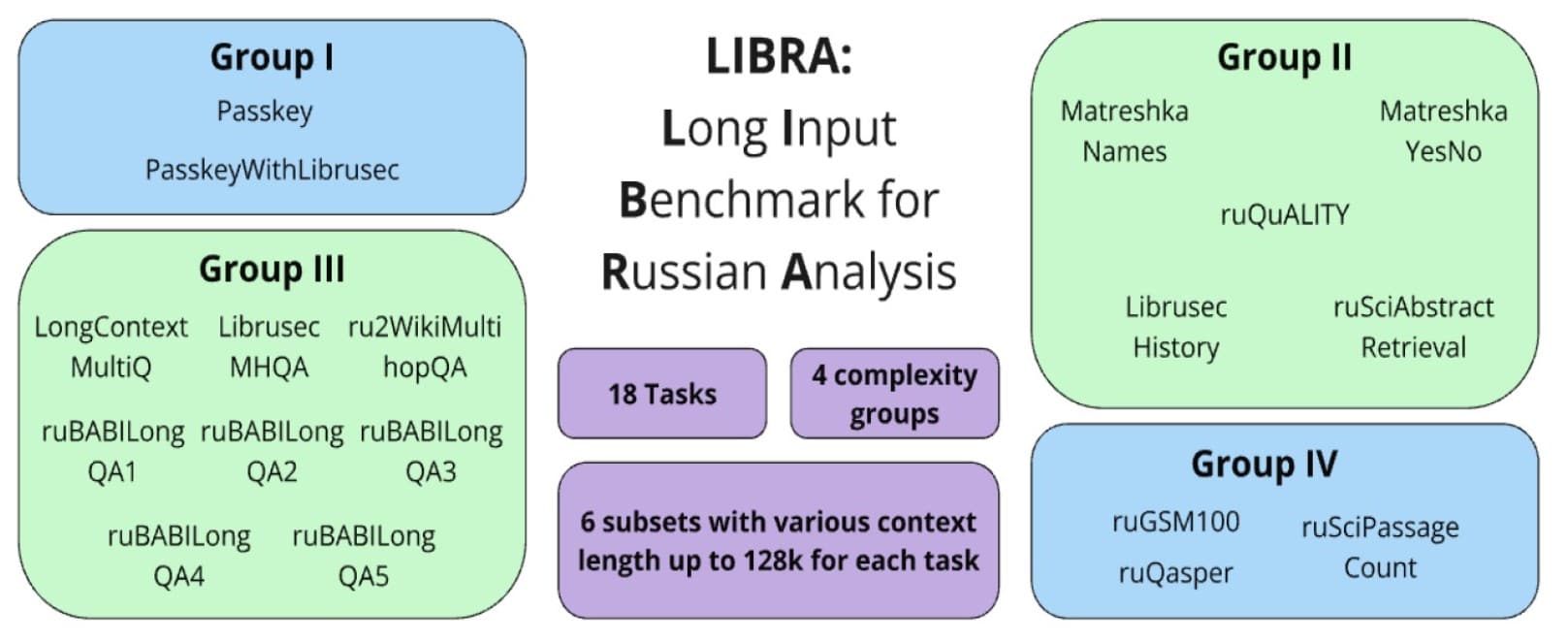
Первая, самая простая группа заданий, работает по принципу «найди иголку в стоге сена». В огромный массив текста помещается короткая, уникальная фраза (например, «ключ доступа»), и задача модели — найти и извлечь ее. Вторая группа усложняет задачу: модели нужно не просто найти информацию, но и ответить на прямой вопрос, основанный на содержании текста. Третья группа требует уже настоящей «детективной работы»: ответ не лежит на поверхности, и для его формулировки нейросети необходимо найти и связать воедино несколько фактов, разбросанных по разным частям документа. Наконец, четвертая, самая сложная группа, требует от модели целостного «понимания» всего контекста и применения логики, включая решение математических задач, описанных в тексте.
Руководитель направления SberAI, доцент ВШЭ Мария Тихонова отметила, что в эпоху стремительного развития искусственного интеллекта критически важно иметь не просто инструменты, но и открытые платформы для совместной работы.
«LIBRA — это не только набор из 18 уникальных задач, но и открытый бенчмарк, доступный всем исследователям: датасеты, код для оценки и публичный лидерборд на HuggingFace. Мы стремились создать «песочницу», где каждый исследователь и разработчик в России мог бы честно и прозрачно тестировать свои модели для работы с длинными текстами, сравнивать результаты и вносить свой вклад», — рассказала Тихонова.
Она выразила надежду, что LIBRA позволит ускорить прогресс в области обработки длинного контекста для русского языка, стимулируя здоровое соревнование и обмен знаниями внутри сообщества.
Как пояснил главный разработчик бенчмарка LIBRA Игорь Чурин, ограниченный «объем памяти» был одним из ключевых препятствий для широкого внедрения LLM в реальные бизнес-процессы и научные исследования, где часто приходится работать с огромными документами.
«Теперь у нас есть инструмент, который позволяет количественно оценивать, как модели действительно ведут себя на масштабных русскоязычных данных — от десятков тысяч токенов до объемов, сравнимых с целой книгой. Мы планируем расширять набор задач, включать новые домены и анализировать тонкие сбои в рассуждениях моделей. Наша цель не просто фиксировать ограничения, а понять их природу и помочь разработчикам создавать системы, которые действительно способны хранить, интерпретировать и использовать большие массивы контекста так же уверенно, как человек», — рассказал Чурин.
Исследователи уже протестировали на своем бенчмарке 17 популярных языковых моделей. Результаты оказались весьма показательными: даже у самых продвинутых систем производительность заметно снижается по мере увеличения длины текста. Это подтверждает, что, несмотря на значительный прогресс, задача глубокого «понимания» действительно больших объемов информации остается одной из самых сложных для современного искусственного интеллекта. Лидером тестов стала модель GPT-4o, а среди моделей с открытыми весами, доступных российскому сообществу, лучший результат показала GLM4-9B-Chat.
Уникальность LIBRA заключается не только в том, что это первый подобный инструмент для русского языка, но и в его комплексности и открытости. Набор из 18 заданий, 14 из которых были созданы специально для этого проекта на основе открытых источников данных, обеспечивает всестороннюю и многогранную оценку. А непереводной характер большинства данных позволяет учитывать специфику российских реалий и культурного кода при оценке, чего невозможно добиться, переводя датасеты с английского. Публикация всех материалов в открытом доступе превращает бенчмарк в живую платформу и точку сборки для всего российского ИИ-сообщества.
«Разработка мощных языковых моделей в России идет полным ходом, но до сих пор у нас не было общего «секундомера» для измерения их производительности в марафонском забеге — обработке длинных текстов. Раньше каждый разработчик тестировал свои модели по-своему, что делало сравнение невозможным. LIBRA — наш ответ на этот вызов. Мы создали единый, открытый и сложный полигон, на котором все желающие могут проверить свои модели в честном соревновании. Предоставляя в открытый доступ не только сами задания, но и код для оценки и публичную таблицу лидеров, мы надеемся стимулировать дальнейшее развитие и совершенствование русскоязычных нейросетей», — прокомментировал научный сотрудник AIRI, исследователь лаборатории нейронных систем и глубокого обучения МФТИ Айдар Булатов.
Команда планирует расширять и усложнять бенчмарк, добавляя в него новые типы заданий и текстовые домены.