



Современные большие языковые модели подобны «черным ящикам». Мы можем восхищаться их способностью писать стихи или программный код, но до недавнего времени практически не понимали, как именно они приходят к своим выводам. Этот недостаток прозрачности — главное препятствие на пути создания по-настоящему безопасного искусственного интеллекта, ведь в глубинах нейронной сети могут скрываться нежелательные предубеждения или опасные логические цепочки. Проблема усугубляется двумя фундаментальными явлениями: полисемантичностью, когда один и тот же нейрон отвечает за несколько несвязанных понятий, и суперпозицией — множество различных признаков «упакованы» в одно и то же математическое пространство. Это похоже на попытку понять смысл романа, в котором каждое слово имеет десяток значений, а предложения могут описывать несколько событий одновременно.
Одним из ключей к расшифровке этого сложного кода стали разреженные автоэнкодеры (SAE) — специальные нейросетевые «словари», которые способны извлекать из активности нейронов отдельные, осмысленные концепции, так называемые моносемантичные признаки. Однако у этого подхода было серьезное ограничение: он позволял заглянуть лишь в один-единственный слой нейросети. Связи между этими концепциями на разных уровнях обработки информации оставались загадкой. Было неясно, является ли понятие «король» на пятом слое тем же самым, что и «король» на двадцатом, или же оно претерпело значительные изменения.
Именно эту задачу — построить мост между отдельными «этажами» нейронной сети — и решили исследователи. Их целью было создать универсальный метод, который мог бы без привлечения огромных массивов данных, лишь анализируя внутреннюю структуру модели, сопоставить признаки на разных слоях и отследить их эволюцию. Команда представила результаты работы на международной конференции ICLR 2025. Статью также опубликовали в виде препринта на научном портале arXiv.
Коллектив ученых разработал алгоритм SAE Match, решающий сложнейшую комбинаторную задачу. Представьте, что у вас есть два словаря для разных языков (два слоя нейросети), в каждом из которых тысячи понятий (признаков). Алгоритм должен найти соответствия, определив, какое понятие из первого словаря наиболее близко по смыслу понятию из второго. SAE Match делает это, минимизируя математическое расстояние между представлениями признаков. Главная сложность — на разных слоях нейросети одни и те же концепции могут иметь разный «масштаб» или «яркость». Решение этой проблемы стало ключевым нововведением. Исследователи разработали технику «свертки параметров» — элегантный математический прием, который учитывает пороги активации признаков и приводит их к единому масштабу перед сравнением. Это позволило добиться очень высокой точности сопоставления.
Результаты экспериментов, проведенных на языковой модели Gemma 2, превзошли все ожидания. Метод не только успешно сопоставлял семантически близкие признаки, что команда подтвердила с помощью внешней большой языковой модели, но и выявил фундаментальные закономерности. Оказалось, большинство концепций в нейросети «живут» и сохраняют свою смысловую стабильность на протяжении примерно пяти слоев, после чего либо исчезают, либо трансформируются во что-то новое. Самым поразительным доказательством эффективности метода стала возможность «хирургического вмешательства» в работу нейросети. Используя созданную карту связей, ученые смогли полностью «вырезать» один из слоев модели, а затем, с помощью своего алгоритма, «перебросить» информацию через образовавшуюся пропасть, соединив предыдущий слой со следующим. Языковая модель практически не потеряла производительность.

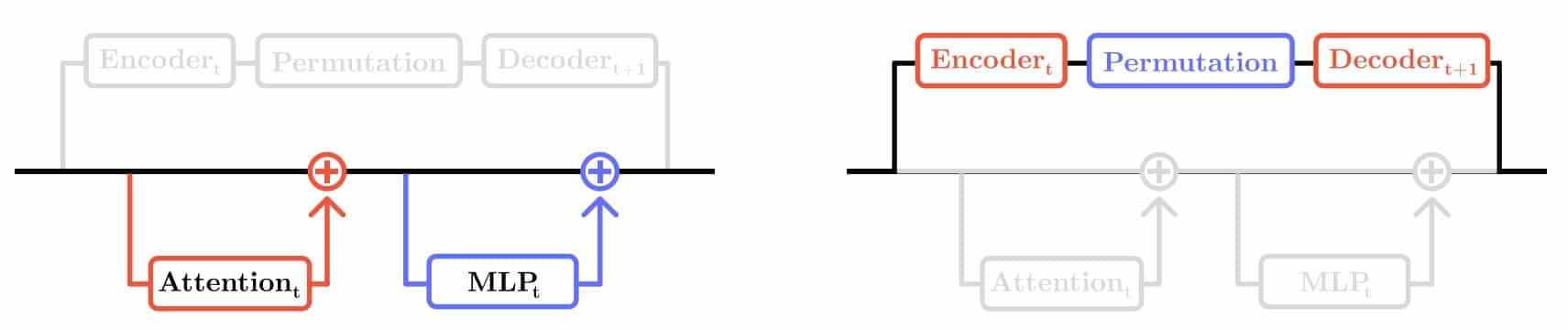
«Хирургия» нейросети: как пропустить целый слой без потери качества. Схематическое изображение эксперимента по «обрезке» слоя. Слева показан стандартный путь обработки информации в нейросети, где она последовательно проходит через все вычислительные блоки. Справа — результат применения метода SAE Match: исследователи, используя свою карту соответствия признаков, «перебрасывают» информацию напрямую с одного слоя на следующий, полностью пропуская промежуточный блок. Успешность этого эксперимента доказывает, что разработанный метод точно описывает внутренние информационные потоки модели / © Nikita Balagansky et al. / ICLR 2025
Никита Балаганский, руководитель научной группы LLM Foundations, T-Bank AI Research, аспирант Московского физико-технического института, пояснил: «С помощью нашего метода можно понять, каким образом концепции образуются и изменяются внутри языковых моделей. В дальнейшем мы сможем более точно изучать и контролировать поведение внутри модели. Возможность пропускать некоторые слои и подставлять нашу «карту» вместо них без потери качества, показывает, что мы верно представляем механизмы внутри».
Главное отличие и преимущество разработанного подхода — его полная независимость от данных. Для построения карты связей не нужно прогонять через модель терабайты текстов. Исследователи анализируют исключительно веса и параметры модели. Это делает метод чрезвычайно эффективным и универсальным. Он не просто описывает, что происходит внутри нейросети, но и позволяет предсказывать ее поведение и даже целенаправленно его изменять.
Во-первых, это мощный инструмент для обеспечения безопасности искусственного интеллекта. Анализируя пути эволюции концепций, можно выявлять и нейтрализовывать скрытые вредоносные или предвзятые логические цепочки. Во-вторых, это путь к оптимизации. Понимая, какие слои или признаки являются избыточными, можно «упрощать» модели, делая их более быстрыми и менее ресурсоемкими без потери производительности. В-третьих, это открывает двери для создания гибридных моделей, где части одной нейросети можно будет эффективно комбинировать с частями другой. В конечном счете, это исследование закладывает основу для перехода от «черных ящиков» к понятным и контролируемым системам искусственного интеллекта.
В будущем это позволит нам не только находить и исправлять ошибки в существующих моделях, но и проектировать новые архитектуры, которые будут более эффективными и безопасными.
В будущем команда планирует составить полные «генеалогические древа» для ключевых концепций в самых больших языковых моделях, а также исследовать более сложные, нелинейные взаимодействия между признаками. Разработанный инструмент может стать стандартом в новой области — механистической интерпретируемости, которая стремится превратить загадочное искусство создания искусственный интеллект в точную науку.