



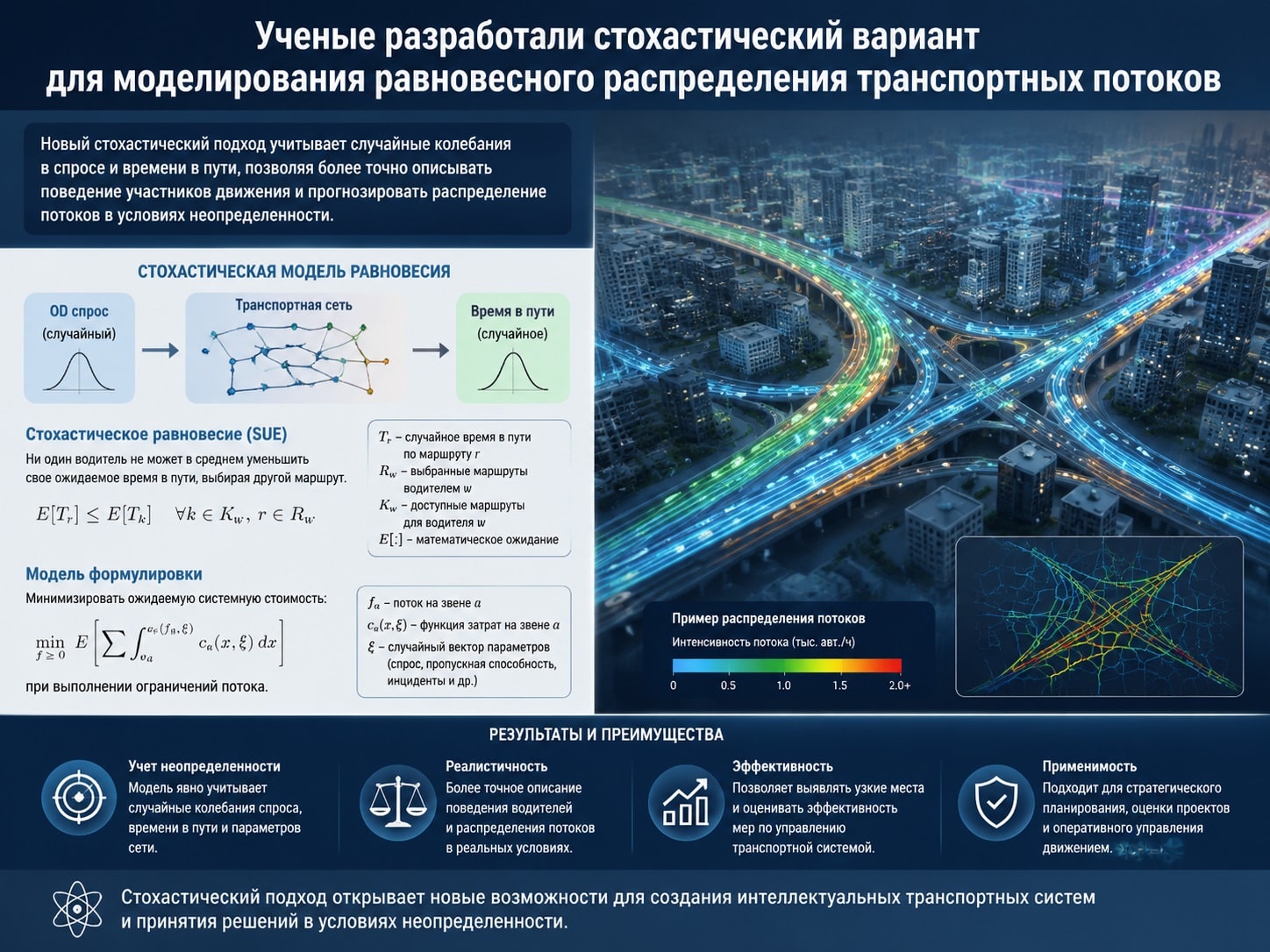
Для краткосрочных прогнозов трафика — от секунд до нескольких часов — применяют методы машинного обучения. Однако для долгосрочного планирования (от дней до десятилетий) инженеры используют математические модели, основанные на равновесном распределении потоков: считается, что каждый водитель выбирает самый быстрый маршрут, а время поездки зависит от загруженности дорог. Классические алгоритмы решения таких задач, в частности метод Франк—Вульфа, на каждом шаге требуют поиска кратчайших путей от всех районов-источников. Для этого используется алгоритм Дейкстры — стандартный способ поиска кратчайших маршрутов на графе дорог. Он пошагово находит минимальное время в пути от одного источника до всех перекрестков, на каждой итерации выбирая ближайший к источнику еще не обработанный узел и проверяя, можно ли через него сократить текущее известное время до соседних узлов. В больших сетях запуск Дейкстры от одного источника занимает секунды, а при тысяче источников одна итерация метода может длиться часами. На крупных дорожных сетях (например, реальные данные по Чикаго, Филадельфии, Бирмингему) это приводит к огромным вычислительным затратам.
Коллектив авторов лаборатории продвинутой комбинаторики и сетевых приложений МФТИ предложил использовать подход, применяемый в машинном обучении: брать для расчета не весь объем данных, а только случайный фрагмент. На каждой итерации алгоритма они случайным образом выбирали небольшую долю (например, 10%) из всех пунктов отправления, формировали пары пункт отправления—пункт назначения и вычисляли кратчайшие пути только для них. При этом время расчетов сокращалось значительно (в 10 раз для выборки 10%), а разница в итоговом распределении потоков была небольшой. Новый метод получил название стохастический вариант метода Франк—Вульфа (Stochastic Origin Frank—Wolfe (SOFW)). Работа, поддержанная грантом Российского научного фонда (проект №21-71-30005-П), опубликована в Journal of Mathematical Sciences.
Платой за ускорение становится увеличение нагрузки на оперативную память. Теперь алгоритм хранит не только суммарный поток транспорта на каждой дороге, но и раздельное хранение потоков по парам отправление—назначение. Это позволяет при следующем шаге изменить потоки машин, учитывая новые кратчайшие пути, только для выбранных пар. В итоге, если мы обсчитываем 10% пар, объем оперативной памяти должен быть увеличен в 10 раз, но при этом мы получим десятикратный выигрыш во времени. На современных вычислительных системах этот компромисс оказывается оправданным. Исследователи также предложили взвешенную версию алгоритма (SOFW‑w). В ней районы, из которых выезжает больше машин, выбираются чаще. Это ускоряет начальную сходимость: за первые итерации ошибка падает быстрее, чем у обычного SOFW.
Соревнование классического и стохастического алгоритмов происходило на реальных дорожных сетях, доступных в открытом репозитории Transportation Networks. Новый метод достигает заданной точности в несколько раз быстрее, что не так критично для маленьких графов (Сиу-Фолс, 24 зоны; Анахайм, 38 зон), но весьма ощутимо на крупных — Филадельфия (1525 зон, 40 тысяч дорог) и Чикаго с окрестностями (1790 зон, 39 тысяч дорог). Десятикратное ускорение на маленькой сети превращает одну тысячу операций в 100 — экономия незаметна. На большой сети те же 10 раз превращают 100 миллионов операций в 10 миллионов, а это уже принципиально. Таким образом, SOFW обеспечивает практический компромисс между качеством решения и вычислительными затратами.

«На мой взгляд, эту работу важно воспринимать не только как алгоритм для оптимизации транспортных потоков, но и как пример более общей идеи: алгоритмы в задачах оптимизации, использующие линейный минимизационный оракул (то есть подпрограмму, которая на каждом шаге находит кратчайшие пути для всех пар откуда—куда), можно существенно ускорить, особенно в задачах большой размерности, где такой оракул является узким местом», — сообщил Игорь Игнашин, сотрудник лаборатории продвинутой комбинаторики и сетевых приложений МФТИ
Авторы подчеркивают, что стохастические методы (основанные на случайном выборе части данных) дают явное преимущество при моделировании крупных транспортных систем. Однако главным направлением для будущих исследований они считают не просто использование своего алгоритма, а распространение самой идеи — внедрение случайного выбора фрагментов данных в другие классические методы оптимизации. В частности, планируется применить такой подход к ускоренным версиям метода Франк—Вульфа и к другим гибридным схемам. Это позволит создавать еще более эффективные и гибкие алгоритмы для расчета равновесного трафика, а также для смежных задач, где требуется многократно искать кратчайшие пути на больших графах.