



Токамак, или тороидальная камера с магнитными катушками, представляет собой установку тороидальной формы (бублика или пончика), в котором создаются условия для протекания управляемого термоядерного синтеза — тех же реакций, что проходят в недрах звезд. С этой целью в токамаках генерируются мощные магнитные поля и создается вакуум для удержания высокотемпературной плазмы и защиты стенок установки от расплавления. Теоретически высвобождаемую в этом процессе энергию можно использовать для производства электроэнергии.
Швейцарский плазменный центр (SPC) Федеральной политехнической школы Лозанны (EPFL) обладает многолетним опытом в области физики плазмы и методов управления ею. Мало того что SPC — один из немногих исследовательских центров в мире, обладающих действующим токамаком, так еще установка у них весьма непростая. Их токамак допускает различные конфигурации плазмы, задаваемых положением магнитных катушек, поэтому и называется токамаком переменной конфигурации (TCV).
Конфигурация плазмы связана с ее формой и положением в токамаке, а от этого зависит устойчивость плазмы и производительность реактора, то есть количество генерируемой энергии. Перед проведением экспериментов на своей установке исследователи из SPC сначала проверяют конфигурации систем управления на симуляторе.

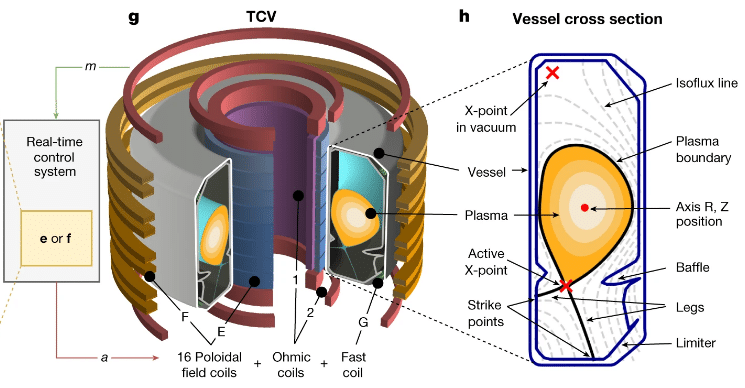
«Наш симулятор основан более чем на 20-летних исследованиях и постоянно обновляется, — поясняет Федерико Феличи (Federico Felici), сотрудник SPC и соавтор исследования. — Но даже в этом случае для определения правильного значения каждой переменной в системе управления по-прежнему необходимы длительные расчеты. Вот тут-то и появляется наш совместный исследовательский проект с DeepMind».
DeepMind — британская компания, занимающаяся научными открытиями и вопросами ИИ, которую Google приобрела в 2014 году и которая стремится «решать проблемы искусственного интеллекта для развития науки и человечества». Эксперты DeepMind разработали алгоритм глубокого обучения с подкреплением (deep reinforcement learning, DRL), который может создавать и поддерживать определенные конфигурации плазмы, и обучили его на симуляторе SPC.
Вначале алгоритм тестировал множество различных стратегий управления плазмой в симуляции для накопления опыта. Причем обучение проходило в две стороны: сначала алгоритму давали ряд настроек для управления установкой, по которым на симуляторе генерировалась плазма, а алгоритм анализировал ее конфигурацию; затем по конфигурации плазмы алгоритмом определялись правильные настройки.

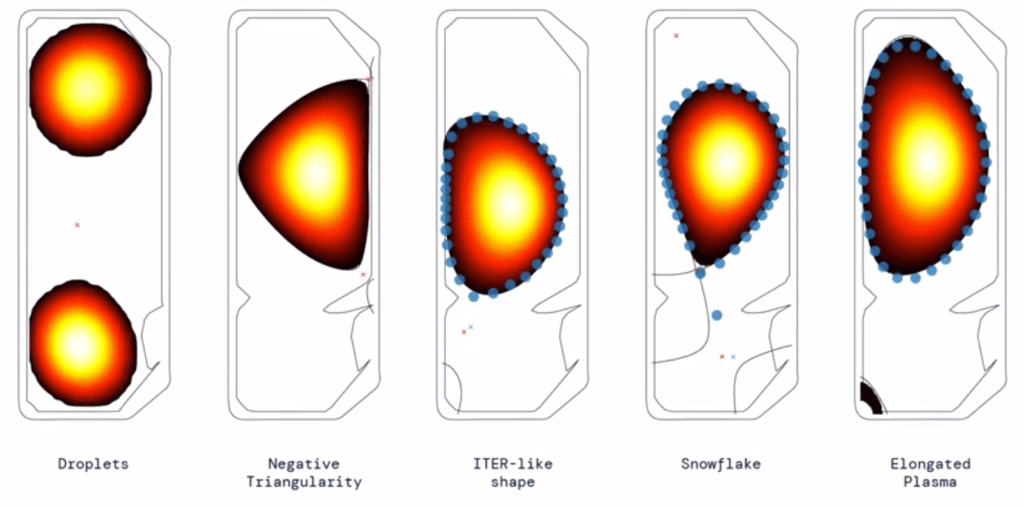
После обучения система на основе алгоритма DRL смогла создавать и поддерживать широкий спектр форм плазмы и расширенных конфигураций в симуляторе, в том числе такую, при которой в реакторе одновременно поддерживаются два отдельных фрагмента плазмы.
Наконец, исследовательская группа протестировала свою новую систему непосредственно на токамаке, чтобы увидеть, как она будет работать в реальных условиях. Как и предполагалось, все созданные алгоритмом DRL и предсказанные симулятором SPC конфигурации удалось получить на реальной установке. Таким образом, новый подход к управлению магнитными катушками токамака не только позволяет ускорить создание необходимых конфигураций плазмы, но и обеспечивает точное отслеживание местоположения, тока и формы для этих конфигураций.
Мартин Ридмиллер (Martin Riedmiller), руководитель группы управления в DeepMind и соавтор исследования, отметил: «Миссия нашей команды состоит в том, чтобы исследовать системы искусственного интеллекта нового поколения — контроллеры с обратной связью, — которые могут обучаться на сложных динамических средах с нуля. Управление термоядерной плазмой в реальных установках предлагает фантастические, хотя и чрезвычайно сложные возможности».
Статья с результатами исследования опубликована в журнале Nature.