



Результаты работы опубликованы в журнале «Доклады Российской академии наук. Математика, информатика, процессы управления».
Создание изображений — занятие творческое, требующее от исполнителя особых навыков и эмоционального настроя. Рисовать, к сожалению, умеет не каждый, да и муза — дама капризная, может долго не посещать. Когда человеку сложно справляться с работой, он стремится делегировать ее технике. По этой причине и благодаря новым возможностям, которые открывают технологии искусственного интеллекта и машинного обучения, появились модели генерации изображений по их описаниям, например DALL-E, Midjourney или Stable Diffusion.
Со временем рынок программного обеспечения стал изобиловать графическими редакторами и онлайн-приложениями. Между тем проблема качественного иллюстрирования не исчезла. Ее наличие обусловлено в том числе трудностями перевода и отсутствием адаптации моделей под национальную культуру. Из-за этого полученные с помощью моделей картинки могут не соответствовать запросу пользователя либо, в худшем случае, нечаянно оскорбить его. На результаты генерации, как правило, сильное влияние оказывает англоязычное информационное поле (рисунок 1).


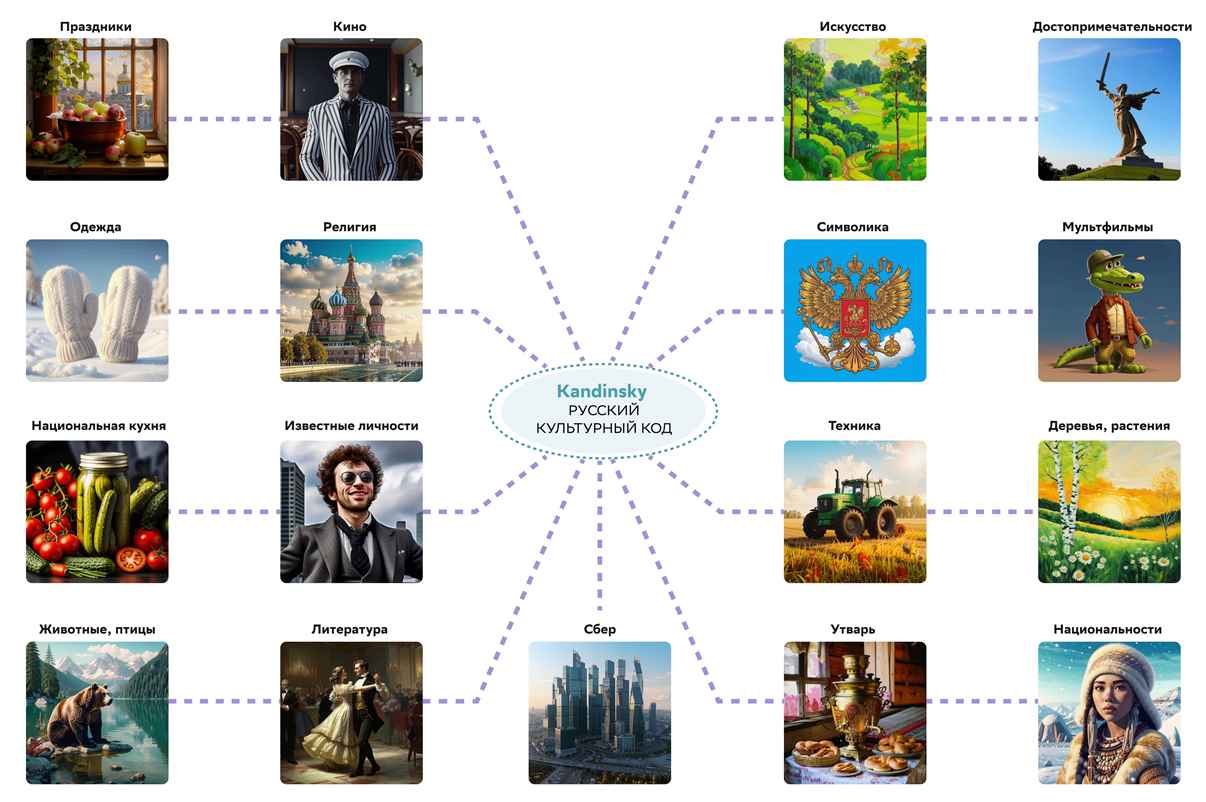
Так как самобытность нации отражается в различных сферах деятельности, ученые выбрали 17 направлений, наиболее значимых для обучения моделей созданию изображений (рисунок 2). Большое внимание уделили особенностям русского языка и литературы, в первую очередь крылатым выражениям и пословицам. Помимо этого были изучены русские традиции и ассоциирующиеся с ними зрительные образы, такие как георгиевская лента — символ Дня Победы, блины и самовар — атрибут Масленицы, Чебурашка — любимый детьми герой сказочной повести Эдуарда Успенского.
Чтобы реализовать методику, ученые вручную обработали около восьми тысяч текстов и иллюстраций к ним из открытых источников в интернете. В процессе обработки и фильтрации были признаны неудовлетворительными и отброшены рисунки, дающие искаженное представление об объекте либо имеющие низкое качество и водяные знаки. Тексты тоже пытались редактировать: удаляли из них многозначные слова и речевые штампы, добавляли имена собственные: названия произведений, имена персонажей. Однако написание нового текста занимало в среднем 4,52 минуты, тогда как корректура существующего — 5,23 минуты, поэтому ученые решили сами излагать сведения об объектах в 2–10 предложениях и переводить их на английский язык. Для устранения ошибок тексты были многократно вычитаны разными лицами.

В итоге удалось собрать около 200 тысяч пар текст-изображение, несущих отпечаток визуальной составляющей культуры. Данные были использованы в двухэтапном процессе дообучения модели Kandinsky 3.1. Общее число шагов оптимизатора на 416 графических процессорах составило 500 тысяч.
«Одно из основных преимуществ нашей модели над мировыми аналогами заключается в наличии данных о русской культуре,— пояснил Вячеслав Васильев, аспирант кафедры дискретной математики МФТИ.— Благодаря этому модель демонстрирует лучшие результаты при решении практических задач, ориентированных на специфику нашей информационной среды».
С целью проверки информационного наполнения модели Kandinsky 3.1 до и после обучения исследователи по описанию сгенерировали внешний вид нескольких объектов: героев русских сказок и мультфильмов, исторических зданий, блюд национальной кухни. Кроме того, разработчики поставили сравнительный эксперимент и задействовали в нем еще пять моделей (рисунки 3 и 4).
«Так как общепринятых правил и формул для определения культурной адаптации генеративных моделей пока не существует, мы разработали собственную методику оценки,— добавил Вячеслав Васильев.— Для этого привлекли людей, и каждому было предложено, руководствуясь рядом критериев, определить лучшее, на его взгляд, изображение, но при этом не зная, какой моделью оно сгенерировано».


Участникам опроса требовалось охарактеризовать рисунки по двум параметрам: соответствие тексту и визуальное качество. Большинство отдали предпочтение рисункам, полученным с помощью модели Kandinsky 3.1. Единственным достойным ее конкурентом назвали DALLE 3. Предыдущая версия Kandinsky 2.2, а также три другие модели: Midjourney 5.2, SDXL и YaART — уступили лидерство.
«Результаты опроса подтвердили эффективность нашей методики сбора данных и обучения модели»,— подвел итог Вячеслав Васильев.
В дальнейшем ученые планируют адаптировать модели для создания видео по тексту, согласно культурным особенностям нашей страны.